Free FPGA: Reimplement the primitives models
We added the AHCI SATA controller Verilog code to the rest of the camera FPGA project, together they now use 84% of the Zynq slices. Building the FPGA bitstream file requires proprietary tools, but all the simulation can be done with just the Free Software – Icarus Verilog and GTKWave. Unfortunately it is not possible to distribute a complete set of the files needed – our code instantiates a few FPGA primitives (hard-wired modules of the FPGA) that have proprietary license.
Please help us to free the FPGA devices for developers by re-implementing the primitives as Verilog modules under GNU GPLv3+ license – in that case we’ll be able to distribute a complete self-sufficient project. The models do not need to provide accurate timing – in many cases (like in ours) just the functional simulation is quite sufficient (combined with the vendor static timing analysis). Many modules are documented in Xilinx user guides, and you may run both the original and replacement models through the simulation tests in parallel, making sure the outputs produce the same signals. It is possible that such designs can be used as student projects when studying Verilog.
The camera project includes more than 200 Verilog files, and it depends on just 29 primitives from the Xilinx simulation library (total number of the files there is 214):
- BUFG.v
- BUFH.v
- BUFIO.v
- BUFMR.v
- BUFR.v
- DCIRESET.v
- GLBL.v
- IBUF.v
- IBUFDS_GTE2.v
- IBUFDS.v
- IDELAYCTRL.v
- IDELAYE2_FINEDELAY.v
- IDELAYE2.v
- IOBUF_DCIEN.v
- IOBUF.v
- IOBUFDS_DCIEN.v
- ISERDESE1.v *
- MMCME2_ADV.v
- OBUF.v
- OBUFT.v
- OBUFTDS.v
- ODDR.v
- ODELAYE2_FINEDELAY.v
- OSERDESE1.v *
- PLLE2_ADV.v
- PS7.v
- PULLUP.v
- RAMB18E1.v
- RAMB36E1.v
This is just a raw list of the unisims modules referenced in the design, it includes PS7.v – a placeholder model of the ARM processing system, modules for AXI functionality simulation are already included in the project. The implementation is incomplete, but sufficient for the the camera simulation and can be used for other Zynq-based projects. Some primitives are very simple (like DCIRESET), some are much more complex. Two modules (ISERDESE1.v and OSERDESE1.v) in the project are the open-source replacements for the encrypted models of the enhanced hardware in Zynq (ISERDESE2.v and OSERDESE2.v) – we used a simple ifdef wrapper that selects reduced (but sufficient for us) functionality of the earlier open source model for simulation and the current “black box” for synthesis.
The files list above includes all the files we need for our current project, as soon as the Free Software replacement will be available we will be able to distribute the self-sufficient project. Other FPGA development projects may need other primitives, so ideally we would like to see all of the primitives to have free models for simulation.
Why is it importantElphel is developing high-performance products based on the FPGA desings that we believe are created for Freedom. We share all the code with our users under GNU General Public License version 3 (or later) but the project depends on proprietary tools distributed by vendors who have monopoly on the tools for their silicon.
There are very interesting projects (like icoBOARD) that use smaller devices with completely Free toolchain (Yosys), but the work of those developers is seriously complicated by non-cooperation of the FPGA vendors. I hope that in the future there will be laws that will limit the monopoly of the device manufacturers and require complete documentation for the products they release to the public. There are advanced patent laws that can protect the FPGA manufacturers and their inventions from the competitors, there is no real need for them to fight against their users by hiding the documentation for the products.
Otherwise this secrecy and “Security through Obscurity” will eventually (and rather soon) lead to a very insecure world where all those self-driving cars, “smart homes” will obey not us, but just the “bad guys” as the current software malware will get to even deeper hardware level. It is very naive to believe that they (the manufacturers) are ultimate masters and have the complete control of “their” devices of ever growing complexity. Unfortunately they do not realize this and are still living in the 20-th century dreams, treating their users as kids who can only play with “Lego blocks” and believe in powerful Wizards who pretend to know everything.
We use proprietary toolchain for implementation, but exclusively Free tools – for simulationOur projects require devices that are more advanced than those that already can be programmed with independently designed Free Software tools, so we have to use the proprietary ones. Freeing the simulation seems to be achievable, and we made a step in this direction – made the whole project simulation possible with the Free Software. Working with the HDL code and simulating it takes most part of the FPGA design cycle, in our experience it is 2/3 – 3/4, and only the remaining part involves running the toolchain and test/troubleshoot the hardware. The last step (hardware troubleshooting) can also be done without any proprietary software – we never used any in this project that utilizes most of the Xilinx Zynq FPGA resources. Combination of the Verilog modules and extensible Python programs that run on the target devices proved to be a working and convenient solution that keeps the developer in the full control of the process. These programs read the Verilog header files with parameter definitions to synchronize register and bit fields addresses between the hardware and the software that uses them.
Important role of the device primitives modelsModern FPGA include many hard-wired embedded modules that supplement the uniform “sea of gates” – addition of such modules significantly increases performance of the device while preserves its flexibility. The modules include memory blocks, DSP slices, PLL circuits, serial-to-parallel and parallel-to-serial converters, programmable delays, high-speed serial transceivers, processor cores and more. Some modules can be automatically extracted by the synthesis software from the source HDL code, but in many cases we have to directly instantiate such primitives in the code, and this code now directly references the device primitives.
The less of the primitives are directly instantiated in the project – the more portable (not tied to a particular FPGA architecture) it is, but in some cases synthesis tools (they are proprietary, so not fixable by the users) incorrectly extract the primitives, in other – the module functionality is very specific to the device and the synthesis tool will not even try to recognize it in the behavioral Verilog code.
Even open source proprietary modules are inconvenientIn earlier days Xilinx was providing all of their primitives models as open source code (but under non-free license), so it was possible to use Free Software tools to simulate the design. But even then it was not so convenient for both our users and ourselves.
It is not possible to distribute the proprietary code with the projects, so our users had to register with the FPGA manufacturer, download the multi-gigabyte software distribution and agree to the specific license terms before they were able to extract those primitives models missing from our project repository. The software license includes the requirement to install mandatory spyware that you give a permission to transfer your files to the manufacturer – this may be unacceptable for many of our users.
It is also inconvenient for ourselves. The primitives models provided by the manufacturer sometimes have problems – either do not match the actual hardware or lack full compatibility with the simulator programs we use. In such cases we were providing patches that can be applied to the code provided by the manufacturer. If Xilinx kept them in a public Git repository, we could base our patches on particular tags or commits, but it is not the case and the manufacturer/software provider preserves the right to change the distributed files at any time without notice. So we have to update the patches to maintain the simulation working even we did not change a single line in the code.
Encrippled modules are unacceptableWhen I started working on the FPGA design for Zynq I was surprised to notice that Xilinx abandoned a practice to provide the source code for the simulation models for the device primitives. The new versions of the older primitives (such as ISERDESE2.v and OSERDESE2.v instead of the previous ISERDESE1.v and OSERDESE1.v) now come in encrippled (crippled by encryption) form while they were open-sourced before. And it is likely this alarming tendency will continue – many proprietary vendors are hiding the source code just because they are not so proud about its quality and can not resist a temptation to encrypt it instead of removing the obsolete statements and updating the code to the modern standards.
Such code is not just inconvenient, it is completely unacceptable for our design process. The first obvious reason is that it is not compatible with the most important development tool – a simulator. Xilinx provides decryption keys to trusted vendors of proprietary simulators and I do not have plans to abandon my choice of the tool just because the FPGA manufacturer prefers a different one.
Personally I would not use any “black boxes” even if Icarus supported them – the nature of the FPGA design is already rather complex to spend any extra time of your life on guessing – why this “black box” behaves differently than expected. And all the “black boxes” and “wizards” are always limited and do not 100% match the real hardware. That is normal, when they cover most of the cases and you have the ability to peek inside when something goes wrong, so you can isolate the bug and (if it is actually a bug of the model – not your code) report it precisely and find the solution with the manufacturer support. Reporting problems in a form “my design does not work with your black box” is rather useless even when you provide all your code – it will be a difficult task for the support team to troubleshoot a mixture of your and their code – something you could do yourself better.
So far we used two different solutions to handle encrypted modules. In one case when the older non-crippled model was available we just used the older version for the new hardware, the other one required complete re-implementation of the GTX serial transceiver model. The current code has many limitations even with its 3000+ lines of code, but it proved to be sufficient for the SATA controller development.
Additional permission under GNU GPL version 3 section 7GNU General Public License Version 3 offers a tool to apply the license in a still “grey area” of the FPGA code. When we were using earlier GPLv2 for the FPGA projects we realized that it was more a statement of intentions than a binding license – FPGA bitstream as well as the simulation inevitably combined free and proprietary components. It was OK for us as the copyright holders, but would make it impossible for others to distribute their derivative projects in a GPL-compliant way. Version 3 has a Section 7 that can be used to give the permission for distribution of the derivative projects that depend on non-free components that are still needed to:
- generate a bitstream (equivalent to a software “binary”) file and
- simulate the design with Free Software tools
The GPL requirement to provide other components under the same license terms when distributing the combined work remains in force – it is not possible to mix this code with any other non-free code. The following is our wording of the additional permission as included in every Verilog file header in Elphel FPGA projects.
Additional permission under GNU GPL version 3 section 7:
If you modify this Program, or any covered work, by linking or combining it
with independent modules provided by the FPGA vendor only (this permission
does not extend to any 3-rd party modules, "soft cores" or macros) under
different license terms solely for the purpose of generating binary "bitstream"
files and/or simulating the code, the copyright holders of this Program give
you the right to distribute the covered work without those independent modules
as long as the source code for them is available from the FPGA vendor free of
charge, and there is no dependence on any encrypted modules for simulating of
the combined code. This permission applies to you if the distributed code
contains all the components and scripts required to completely simulate it
with at least one of the Free Software programs.
Xilinx has User Guides files available for download on their web site, some of the following links include release version and may change in the future. These files provide valuable information needed to re-implement the simulation models.
- UG953 Vivado Design Suite 7 Series FPGA and Zynq-7000 All Programmable SoC Libraries Guide lists all the primitives, their I/O ports and attributes
- UG474 7 Series FPGAs Configurable Logic Block has description of the CLB primitives
- UG473 7 Series FPGAs Memory Resources has description for Block RAM modules, ports, attributes and operation of these modules
- UG472 7 Series FPGAs Clocking Resources provides information for the clock buffering (BUF*) primitives and clock management tiles – MMCM and PLL primitives of the library
- UG471 7 Series FPGAs SelectIO Resources covers advanced I/O primitives, including DCI, programmable I/O delays elements and serializers/deserializers, I/O FIFO elements
- UG476 7 Series FPGAs GTX/GTH Transceivers is dedicated to the high speed serial transceivers. Simulation models for these modules are partially re-implemented for use in AHCI SATA Controller.
AHCI platform driver
AHCI PLATFORM DRIVER
In kernels prior to 2.6.x AHCI was only supported through PCI and hence required custom patches to support platform AHCI implementation. All modern kernels have SATA support as part of AHCI framework which significantly simplifies driver development. Platform drivers follow the standard driver model convention which is described in Documentation/driver-model/platform.txt in kernel source tree and provide methods called during discovery or enumeration in their platform_driver structure. This structure is used to register platform driver and is passed to module_platform_driver() helper macro which replaces module_init() and module_exit() functions. We redefined probe() and remove() methods of platform_driver in our driver to initialize/deinitialize resources defined in device tree and allocate/deallocate memory for driver specific structure. We also opted to resource-managed function devm_kzalloc() as it seems to be preferred way of resource allocation in modern drivers. The memory allocated with resource-managed function is associated with the device and will be freed automatically after driver is unloaded.
HARDWARE LIMITATIONSAs Andrey has already pointed out in his post, current implementation of AHCI controller has several limitations and our platform driver is affected by two of them.
First, there is a deviation from AHCI specification which should be considered during platform driver implementation. The specification defines that host bus adapter uses system memory for the Command List Structure, Received FIS Structure and Command Tables. The common approach in platform drivers is to allocate a block of system memory with single dmam_alloc_coherent() call, set pointers to different structures inside this block and store these pointers in port specific structure ahci_port_priv. The first two of these structures in x393_sata are stored in the FPGA RAM blocks and mapped to register memory as it was easier to make them this way. Thus we need to allocate a block of system memory for Command Tables only and set other pointers to predefined addresses.
Second, and the most significant one from the driver’s point of view, proved to be single command slot implemented. Low level drivers assume that all 32 slots in Command List Structure are implemented and explicitly use the last slot for internal commands in ata_exec_internal_sg() function as shown in the following code snippet:
struct ata_queued_cmd *qc;
unsigned int tag, preempted_tag;
if (ap->ops->error_handler)
tag = ATA_TAG_INTERNAL;
else
tag = 0;
qc = __ata_qc_from_tag(ap, tag);
ATA_TAG_INTERNAL is defined in libata.h and reserved for internal commands. We wanted to keep all the code of our driver in our own sources and make as fewer changes to existing Linux drivers as possible to simplify further development and upgrade to newer kernels. So we decided that substitution of the command tag in our own code which handles command preparation would be the easiest way of fixing this issue.
DRIVER STRUCTURESProper platform driver initialization requires that several structures to be prepared and passed to platform functions during driver probing. One of them is scsi_host_template and it serves as a direct interface between middle level drivers and low level drivers. Most AHCI drivers use default AHCI_SHT macro to fill the structure with predefined values. This structure contains a field called .can_queue which is of particular interest for us. The .can_queue field sets the maximum number of simultaneous commands the host bus adapter can accept and this is the way to tell middle level drivers that our controller has only one command slot. The scsi_host_template structure was redefined in our driver as follows:
static struct scsi_host_template ahci_platform_sht = {
AHCI_SHT(DRV_NAME),
.can_queue = 1,
.sg_tablesize = AHCI_MAX_SG,
.dma_boundary = AHCI_DMA_BOUNDARY,
.shost_attrs = ahci_shost_attrs,
.sdev_attrs = ahci_sdev_attrs,
};
Unfortunately, ATA layer driver does not take into consideration the value we set in this template and uses hard coded tag value for its internal commands as I pointed out earlier, so we had to fix this in command preparation handler.
ata_port_operations is another important driver structure as it controls how the low level driver interfaces with upper layers. This structure is defined as follows:
static struct ata_port_operations ahci_elphel_ops = {
.inherits = &ahci_ops,
.port_start = elphel_port_start,
.qc_prep = elphel_qc_prep,
};
The port start and command preparation handlers were redefined to add some implementation specific code. .port_start is used to allocate memory for Command Table and set pointers to Command List Structure and Received FIS Structure. We decided to use streaming DMA mapping instead of coherent DMA mapping used in generic AHCI driver as explained in Andrey’s article. .qc_prep is used to change the tag of current command and organize proper access to DMA mapped buffer.
We used debug code in the driver along with profiling code in the controller to estimate overall performance and found out that upper driver layers introduce significant delays in command execution sequence. The delay between last DMA transaction in a sequence of transactions and next command could be as high as 2 ms. There are various sources of overhead which could lead to delays, for instance, file system operations and context switches in the operating system. We will try to use read/write operations on a raw device to improve performance.
LINKSAHCI/SATA stack under GNU GPL
GitHub: AHCI driver source code
AHCI/SATA stack under GNU GPL
Implementation includes AHCI SATA host adapter in Verilog under GNU GPLv3+ and a software driver for GNU/Linux running on Xilinx Zynq. Complete project is simulated with Icarus Verilog, no encrypted modules are required.
This concludes the last major FPGA development step in our race against finished camera parts and boards already arriving to Elphel facility before the NC393 can be shipped to our customers.
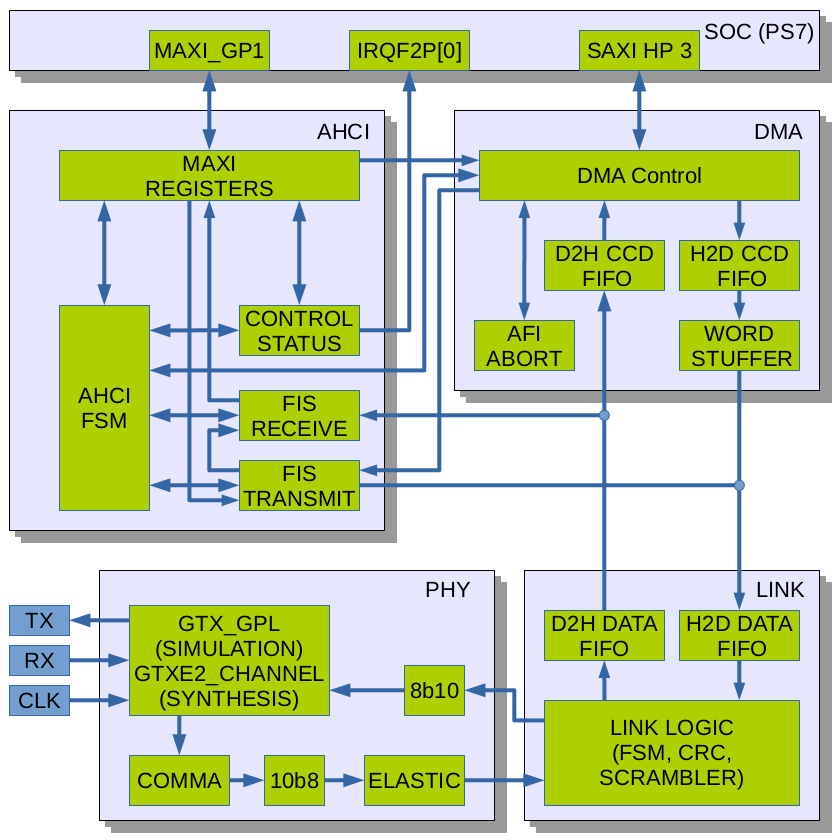{kind=link}
Fig. 1. AHCI Host Adapter block diagram
Why did we need SATA?
Elphel cameras started as network cameras – devices attached to and controlled over the Ethernet, the previous generations used 100Mbps connection (limited by the SoC hardware), and NC393 uses GigE. But this bandwidth is still not sufficient as many camera applications require high image quality (compared to “raw”) without compression artifacts that are always present (even if not noticeable by the human viewer) with the video codecs. Recording video/images to some storage media is definitely an option and we used it in the older camera too, but the SoC IDE controller limited the recording speed to just 16MB/s. It was about twice more than the 100Mb/s network, but still was a bottleneck for the system in many cases. The NC393 can generate 12 times the pixel rate (4 simultaneous channels instead of a single one, each running 3 times faster) of the NC353 so we need 200MB/s recording speed to keep the same compression quality at the increased maximal frame rate, higher recording rate that the modern SSD are capable of is very desirable.
{kind=link}
Fig.2. SATA routing: a) Camera records data to the internal SSD; b) Host computer connects directly to the internal SSD; c) Camera records to the external mass storage device
The most universal ways to attach mass storage device to the camera would be USB, SATA and PCIe. USB-2 is too slow, USB-3 is not available in Xilinx Zynq that we use. So what remains are SATA and PCIe. Both interfaces are possible to implement in Zynq, but PCIe (being faster as it uses multiple lanes) is good for the internal storage while SATA (in the form of eSATA) can be used to connect external storage devices too. We may consider adding PCIe capability to boost recording speed, but for initial implementation the SATA seems to be more universal, especially when using a trick we tested in Eyesis series of cameras for fast unloading of the recorded data.
Routing SATA in the cameraIt is a solution similar to USB On-The-Go (similar term for SATA is used for unrelated devices), where the same connector is used to interface a smartphone to the host PC (PC is a host, a smartphone – a device) and to connect a keyboard or other device when a phone becomes a host. In contrast to the USB cables the eSATA ones always had identical connectors on both ends so nothing prevented to physically link two computers or two external drives together. As eSATA does not carry power it is safe to do, but nothing will work – two computers will not talk to each other and the storage devices will not be able to copy data between them. One of the reasons is that two signal pairs in SATA cable are uni-directional – pair A is output for the host and input for device, pair B – the opposite.
Camera uses Vitesse (now Microsemi) VSC3304 crosspoint switch (Eyesis uses larger VSC3312) that has a very useful feature – it has reversible I/O ports, so the same physical pins can be configured as inputs or outputs, making it possible to use a single eSATA connector in both host and device mode. Additionally VSC3304 allows to change the output signal level (eSATA requires higher swing than the internal SATA) and perform analog signal correction on both inputs and outputs facilitating maintaining signal integrity between attached SATA devices.
Aren’t SATA implementations for Xilinx Zynq already available?Yes and no. When starting the NC393 development I contacted Ashwin Mendon who already had SATA-2 working on Xilinx Virtex. The code is available on OpenCores under GNU GPL license. There is an article published by IEEE . The article turned out to be very useful for our work, but the code itself had to be mostly re-written – it was still for different hardware and were not able to simulate the core as it depends on Xilinx proprietary encrypted primitives – a feature not compatible with the free software simulators we use.
Other implementations we could find (including complete commercial solution for Xilinx Zynq) have licenses not compatible with the GNU GPLv3+, and as the FPGA code is “compiled” to a single “binary” (bitstream file) it is not possible to mix free and proprietary code in the same design.
The SATA host adapter is implemented for Elphel NC393 camera, 10393 system board documentation is on our wiki page. The Verilog code is hosted at GitHub, the GNU/Linux driver ahci_elphel.c is also there (it is the only hardware-specific driver file required). The repository contains a complete setup for simulation with Icarus Verilog and synthesis/implementation with Xilinx tools as a VDT (plugin for Eclipse IDE) project.
Current limitationsThe current project was designed to be a minimal useful implementation with provisions to future enhancements. Here is the list of what is not yet done:
- It is only SATA2 (3GHz) while the hardware is SATA3(6GHz) capable. We will definitely work on the SATA3 after we will complete migration to the new camera platform. Most of the project modules are already designed for the higher data rate.
- No scrambling of outgoing primitives, only recognizing incoming ones. Generation of CONTp is optional by SATA standard, but we will definitely add this as it reduces EMI and we already implemented multiple hardware measures in this direction. Most likely we will need it for the CE certification.
- No FIS-based switching for port multipliers.
- Single command slot, and no NCQ. This functionality is optional in AHCI, but it will be added – not much is missing in the current design.
- No power management. We will look for the best way to handle it as some of the hardware control (like DevSleep) requires i2c communication with the interface board, not directly under FPGA control. Same with the crosspoint switch.
There is also a deviation from the AHCI standard that I first considered temporary but now think it will stay this way. AHCI specifies that a Command list structure (array of 32 8-DWORD command headers) and a 256-byte Received FIS structure are stored in the system memory. On the other hand these structures need non-paged memory, are rather small and require access from both CPU and the hardware. In x393_sata these structures are mapped to the register memory (stored in the FPGA RAM blocks) – not to the regular system memory. When working with the AHCI driver we noticed that it is even simpler to do it that way. The command tables themselves that involve more data passing form the software to device (especially PRDT – physical region descriptor tables generated from the scatter-gather lists of allocated data memory) are stored in the system memory as required and are read to the hardware by the DMA engine of the controller.
As of today the code is still not yet cleaned up from temporary debug additions. It will all be done in the next couple weeks as we need to combine this code with the large camera-specific code – SATA controller (~6% of the FPGA resources) was developed separately from the rest of the code (~80% resources) as it makes both simulation and synthesis iterations much faster.
ExtrasThis implementation includes some additions functionality controlled by Verilog `ifdef directives. Two full block RAM primitives as used for capturing data in the controller. One of these “datascopes” captures incoming data right after 10b/8b decoder – it can store either 1024 samples of the incoming data combined of 16 bit of data plus attributes or the compact form when each 32-bit primitive is decoded and the result is a 5-bit primitive/error number. In that case 6*1024 primitives are recorded – 3 times longer than the longest FIS.
Another 4KB memory block is used for profiling – the controller timestamps and records first 5 DWORDs of each each incoming and outgoing FIS, additionally it timestamps software writes to the specific location allowing mixed software/hardware profiling.
This project implements run-time access to the primitive attributes using Xilinx DRP port of the GTX elements, same interface is used to programmatically change the logical values of the configuration inputs, making it significantly simpler to guess how the partially documented attributes change the device functionality. We will definitely need it when upgrading to SATA3.
Code description Top connectionsThe controller uses 3 differential I/O pads of the device – one input pair (RX on Fig.1) and one output pair (TX) make up a SATA port, additional dedicated input pair (CLK) provides 150MHz that synchronizes most of the controller and the transmit channel of the Zynq GTX module. In the 10393 board uses SI53338 spread-spectrum capable programmable clock to drive this input.
Xilinx conventions tell that the top level module should instantiate the SoC Processing System PS7 (I would consider connections to the PS7 as I/O ports), so the top module does exactly that and connects to AXI ports of the actual design top module to the MAXIGP1 and SAXIHP3 ports of the PS7, IRQF2P[0] provides interrupt signal to the CPU. MAXIGP1 is one of the two 32-bit AXI ports where CPU is master – it is used for PIO access to the controller register memory (and read out debug information), SAXIHP3 is one of the 4 “high performance” 64-bit wide paths, this port is used by the controller DMA engine to transfer command tables and data to/from the device. The port numbers are selected to match ones unused in the camera specific code, other designs may have different assignments.
Clocks and clock domainsCurrent SATA2 implementation uses 4 different clock domains, some may be shared with other unrelated modules or have the same source.
- aclk is used in MAXIGP1 channel and part of the MAXI REGISTERS module synchronizing AXI-pointing port of the dual-port block RAM that implements controller registers. 150 MHz (maximal permitted frequency) is used, it is generated from one of the PS7 FPGA clocks
- hclk is used in AXI HP3 channel, DMA Control and parts of the H2D CCD FIFO (host-to-device cross clock domain FIFO ), D2H CCD FIFO and AFI ABORT modules synchronizing. 150 MHz (maximal permitted frequency) is used, same as the aclk
- mclk is used throughout most of the other modules of the controller except parts of the GTX, COMMA, 10b8 and input parts of the ELASTIC. For current SATA2 implementation it is 75MHz, this clock is derived from the external clock input and is not synchronous with the first two
- xclk – source-synchronous clock extracted from the incoming SATA data. It drives COMMA and 10b8 modules, ELASTIC allows data to cross clock boundaries by adding/removing ALIGNp primitives
The two lower layers of the stack (phy and link) that are independent of the controller system interface (AHCI) are instantiated in ahci_sata_layers.v module together with the 2 FIFO buffers for D2H (incoming) and H2D outgoing data.
SATA PHYSATA PHY layer Contains the OOB (Out Of Band) state machine responsible for handling COMRESET,COMINIT and COMWAKE signals, the rest is just a wrapper for the functionality of the Xilinx GTX transceiver. This device includes both high-speed elements and some blocks that can be synthesized using FPGA fabric. Xilinx does not provide the source code for the GTX simulation module and we were not able to match the hardware operation to the documentation, so in the current design we use only those parts of the GTXE2_CHANNEL primitive that can not be replaced by the fabric. Other modules are implemented as regular Verilog code included in the x393_sata project. There is a gtx_wrap module in the design that has the same input/output ports as the primitive allowing to select which features are handled by the primitive and which – by the Verilog code without changing the rest of the design.
The GTX primitive itself can not be simulated with the tools we use, so the simulation module was replaced, and Verilog `ifdef directive switches between the simulation model and non-free primitive for synthesis. The same approach we used earlier with other Xilinx proprietary primitives.
Link module implements SATA link state machine, scrambling/descrambling of the data, calculates CRC for transmitted data and verifies CRC for the received one. SATA does not transmit and receive data simultaneously (only control primitives), so both CRC and scrambler modules have a single instance each providing dual functionality. This module required most troubleshooting and modifications during testing the hardware with different SSD – at some stages controller worked with some of them, but not with others.
ahci_topOther modules of the design are included in the ahci_top. Of them the largest is the DMA engine shown as a separate block on the Fig.1.
DMADMA engine makes use of one of the Zynq 64-bit AXI HP ports. This channel includes FIFO buffers on the data and address subchannels (4 total) – that makes interfacing rather simple. The hard task is resetting the channels after failed communication of the controller with the device – even reloading bitsteam and resetting the FPGA would not help (actually it makes things even worse). I searched Xilinx support forum and found that similar questions where only discussed between the users, there was no authoritative recommendation from Xilinx staff. I added axi_hp_abort module that watches over the I/O transactions and keeps track of what was sent to the FIFO buffers, being able to complete transactions and drain buffers when requested.
The DMA module reads command table, saves command data in the memory block to be later read by the FIS TRANSMIT module, it then reads the scatter-gather memory descriptors (PRDT) (supporting pre-fetch if enabled) and reads/writes the data itself combining the fragments.
On the controller side data that comes out towards the device (H2D CCD FIFO) and coming from device(D2H CCD FIFO) needs to cross the clock boundary between hclk and mclk, and handle alignment issues. AXI HP operates in 64-bit mode, data to/from the link layer is 32-bit wide and AHCI allows alignment to the even number of bytes (16bits). When reading from the device the cross-clock domain FIFO module does it in a single step, combining 32-bit incoming DWORDs into 64-bit ones and using a barrel shifter (with 16-bit granularity) to align data to the 64-bit memory QWORDs – the AXI HP channel provides per-byte write mask that makes it rather easy. The H2D data is converted in 2 steps: First it crosses the clock domain boundary being simultaneously transformed to 32-bit with a 2-bit word mask that tells which of the two words in each DWORD are valid. Additional module WORD STUFFER operates in mclk domain and consolidates incoming sparse DWORDs into full outgoing DWORDs to be sent to the link layer.
AHCIThe rest of the ahci_top module is shown as AHCI block. AHCI standard specifies multiple registers and register groups that HBA has. It is intended to be used for PCI devices, but the same registers can be used even when no PCI bus is physically present. The base address is programmed differently, but the relative register addressing is still the same.
MAXI REGISTERSMAXI REGISTERS module provides the register functionality and allows data to cross the clock domain boundary. The register memory is made of a dual-port block RAM module, additional block RAM (used as ROM) is pre-initialized to make each bit field of the register bank RW (read/write), RO (read only), RWC (read, write 1 to clear) or RW1 (read, write 1 to set) as specified by the AHCI. Such initialization is handled by the Python program create_ahci_registers.py that also generates ahci_localparams.vh include file that provides symbolic names for addressing register fields in Verilog code of other modules and in simulation test benches. The same file runs in the camera to allow access to the hardware registers by names.
Each write access to the register space generates write event that crosses the clock boundary and reaches the HBA logic, it is also used to start the AHCI FSM even if it is in reset state.
The second port of the register memory operates in mclk domain and allows register reads and writes by other AHCI submodules (FIS RECEIVE – writes registers, FIS TRANSMIT and CONTROL STATUS)
The same module also provides access to debug registers and allows reading of the “datascope” acquired data.
CONTROL STATUSThe control/status module maintains “live” registers/bits that the controller need to react when they are changed by the software and react on various events in the different parts of the controller. The updated register values are written to the software accessible register bank.
This module generates interrupt request to the processor as specified in the AHCI standard. It uses one of the interrupt lines from the FPGA to the CPU (IRQF2P) available in Zynq.
AHCI FSMThe AHCI state machine implements the AHCI layer using programmable sequencer. Each state traverses the following two stages: actions and conditions. The first stage triggers single-cycle pulses that are distributed to appropriate modules (currently 52 total). Some actions require just one cycle, others wait for “done” response from the destination. Conditions phase involves freezing logical conditions (now 44 total) and then going through them in the order specified in AHCI documentation. The state description for the machine is provided in the Assembler-like format inside the Python program ahci_fsm_sequence.py it generates Verilog code for the action_decoder.v and condition_mux.v modules that are instantiated in the ahci_fsm.v.
The output listing of the FSM generator is saved to ahci_fsm_sequence.lst. Debug output registers include address of the last FSM transition, so this listing can be used to locate problems during hardware testing. It is possible to update the generated FSM sequence at run time using designated as vendor-specific registers in the controller I/O space.
FIS RECEIVEThe FIS RECEIVE module processes incoming FIS (DMA Setup FIS, PIO Setup FIS, D2H register FIS, Set device bits FIS, unknown FIS), updates required registers and saves them in the appropriate areas of received FIS structure. For incoming data FIS it consumes just the header DWORD and redirects the rest to the D2H CCD FIFO of the DMA module. This module also implements the word counters (PRD byte count and decrementing transfer counter), these counters are shared with the transmit channel.
FIS TRANSMITFIS TRANSMIT module recognizes the following commands received from the AHCI FSM: fetch_cmd, cfis_xmit, atapi_xmit and dx_xmit, following the prefetch condition bit. The first command (fetch_cmd) requests DMA engine to read in the command table and optionally to prefetch PRD memory descriptors. The command data is read from the DMA module memory after one of the cfis_xmit or atapi_xmit comamnds, it is then transmitted to the link layer to be sent to device. When processing the dx_xmit this module sends just the header DWORD and transfers control to the DMA engine, continuing to count PRD byte count and decrementing transfer counter.
FPGA resources usedAccording to the “report_utilization” Xilinx Vivado command, current design uses:
- 1358 (6.91%) slices
- 9.5 (3.58%) Block RAM tiles
- 7 (21.88%) BUFGCTRL
- 2 (40%) PLLE2_ADV
The resource usage will be reduced as there are debug features not yet disabled. One of the PLLE2_ADV uses clock already available in the rest of the x393 code (150MHz for MAXIGP1 and SXAHIHP3), the other PLL that produces 75MHz transmit-synchronous clock can probably be eliminated too. Two of the block RAM tiles are capturing incoming primitives and profiling data, this functionality is not needed in the production version. More the resources may be saved if we’ll be able to use the hard-wired 10b/8b decoder, 8b/10b encoder, comma alignment and elastic buffer primitives of the Xilinx GTXE2_CHANNEL.
Testing the hardware Testing with Python programsAll the initial work with the actual hardware was done with the Python script that started with reimplementation of the same functionality used when simulating the project. Most is in x393sata.py that imports x393_vsc3304.py to control the VSC3304 crosspoint switch. This option turned out very useful for troubleshooting starting from initial testing of the SSD connection (switch can route the SSD to the desktop computer), then for verifying the OOB exchange (the only what is visible on my oscilloscope) – switch was set to connect SSD to Zynq, and use eSATA connector pins to duplicate signals between devices, so probing did not change the electrical characteristics of the active lines. Python program allowed to detect communication errors, modify GTX attributes over DRP, capture incoming data to reproduce similar conditions with the simulator. Step-by-step it was possible to receive signature FIS, then get then run the identify command. In these tests I used large area of the system memory that was reserved as a video ring buffer set up as “coherent” DMA memory. We were not able to make it really “coherent” – the command data transmitted to the device (controller reads it from the system memory as a master) often contained just zeros as the real data written by the CPU got stuck in either one of the caches or in the DDR memory controller write buffer. These errors only went away when we abandoned the use of the coherent memory allocation and switched to the stream DMA with explicit synchronization with dma_sync_*_for_cpu/dma_sync_*_for_device.
AHCI driver for GNU/LinuxMikhail Karpenko is preparing post about the software driver, and as expected this development stage revealed new controller errors that were not detected with just manual launching commands through the Python program. When we mounted the SSD and started to copy gigabyte files, the controller reported some fake CRC errors. And it happened with one SSD, but not with the other. Using data capturing modules it was not so difficult to catch the conditions that caused errors and then reproduce them with the simulator – one of the last bugs detected was that link layer incorrectly handled single incoming HOLD primitives (rather unlikely condition).
Performance resultsFirst performance testing turned out to be rather discouraging – ‘dd’ reported under 100 MB/s rate. At that point I added profiling code to the controller, and the data rate for the raw transfers (I tried command that involved reading of 24 of the 8KB FISes), measured from the sending of the command FIS to the receiving of the D2H register FIS confirming the transfer was 198MB/s – about 80% of the maximal for the SATA2. Profiling the higher levels of the software we noticed that there is virtually no overlap between the hardware and software operation. It is definitely possible to improve the result, but the fact that the software slowed twice the operation tells that it if the requests and their processing were done in parallel, it will consume 100% of the CPU power. Yes, there are two cores and the clock frequency can be increased (the current boards use the speed grade 2 Zynq, while the software still thinks it is speed grade 1 for compatibility with the first prototype), it still may be a big waste in the camera. So we will likely bypass the file system for sequential recording video/images and use the second partition of the SSD for raw recording, especially as we will record directly from the video buffer of the system memory, so no dealing with scatter-gather descriptors, and no need to synchronize system memory as no cache is involved. The memory controller is documented as being self-coherent, so reading the same memory while it is being written to through a different channel should cause write operation to be performed first.
Conclusions and future plansWe’ve achieved the useful functionality of the camera SATA controller allowing recording to the internal high capacity m.2 SSD, so all the hardware is tested and cameras can be shipped to the users. The future upgrades (including SATA3) will be released in the same way as other camera software. On the software side we will first need to upgrade our camogm recorder to reduce CPU usage during recording and provide 100% load to the SATA controller (rather easy when recording continuous memory buffer). Later (it will be more important after SATA3 implementation) we may optimize controller even more try to short-cut the video compressors outputs directly to the SATA controller, using the system memory as a buffer only when the SSD is not ready to receive data (they do take “timeouts”).
We hope that this project will be useful for other developers who are interested in Free Software solutions and prefer the Real Verilog Code (RVC) to all those “wizards”, “black boxes” and “IP”.
Software tools used (and not)Elphel designs and builds high performance cameras striving to provide our users/developers with the design freedom at every possible level. We do not use any binary-only modules or other hidden information in our designs – all what we know ourselves is posted online – usually on GitHub and Elphel Wiki. When developing FPGA, and that unfortunately still depends on proprietary tools, we limit ourselves to use only free for download tools to be exactly in the same position as many of our users. We can not make it necessary for the users (and consider it immoral) to purchase expensive tools to be able to modify the free software code for the hardware they purchased from Elphel, so no “Chipscopes” or other fancy proprietary tools were used in this project development.
Keeping information free is a precondition, but it is not sufficient alone for many users to be able to effectively develop new functionality to the products, there needs to be ease of doing that. In the area of the FPGA design (and it is a very powerful tool resulting in high performance that is not possible with just software applications) we think of our users as smart people, but not necessarily professional FPGA developers. Like ourselves.
{kind=link}
Fig.3 FPGA development with VDT
We learned a lesson from our previous FPGA projects that depended too much on particular releases of Xilinx tools and were difficult to maintain even for ourselves. Our current code is easier to use, port and support, we tried to minimize dependence on particular tools used what we think is a better development environment. I believe that the “Lego blocks” style is not the the most productive way to develop the FPGA projects, and it is definitely not the only one possible.
Treating HDL code similar to the software one is not less powerful paradigm, and to my opinion the development tools should not pretend to be “wizards” who know better than me what I am allowed (or not allowed) to do, but more like gentle secretaries or helpers who can take over much of routine work, remind about important events and provide some appropriate suggestions (when asked for). Such behavior is even more important if the particular activity is not the only one you do and you may come back to it after a long break. A good IDE should be like that – help you to navigate the code, catch problems early, be useful with default settings but provide capabilities to fine tune the functionality according to the personal preferences. It is also important to provide familiar environment, this is why we use the same Eclipse IDE for Verilog, Python, C/C++ and Java and more. All our projects come with the initial project settings files that can be imported in this IDE (supplemented by the appropriate plugins) so you can immediately start development from the point we currently left it.
For FPGA development Elphel provides VDT – a powerful tool that includes deep Verilog support and integrates free software simulator Icarus Verilog with the Github repository and a popular GTKWave for visualizing simulation results. It comes with the precofigured support of FPGA vendors proprietary synthesis and implementation tools and allows addition of other tools without requirement to modify the plugin code. The SATA project uses Xilinx Vivado command line tools (not Vivado GUI), support for several other FPGA tools is also available.
NC393 camera is fit for flight
The components for 10393 and other related circuit boards for the new NC393 camera series have been ordered and contract manufacturing (CM) is ready to assemble the first batch of camera boards.
In the meantime, the extruded parts that will be made into NC393 camera body have been received at Elphel. The extrusion looks very slick with thin, 1mm walls made out of strong 6061-T6 aluminium, and weighs only 55g. The camera’s new lightweight design is suitable for use on a small aircraft. The heat frame responsible for cooling the powerful processor has also been extruded.
We are very pleased with the performance of Profile Precision Extrusions located in Phoenix, Arizona, which have delivered a very accurate product ahead of the proposed schedule. Now we can proudly engrave “Made in USA” on the camera, as now even the camera body parts are made in the United States.
Of course, we have tried to order the extrusion in China, but the intricately detailed profile is difficult to extrude and tolerances were hard to match, so when Profile Precision was recommended to us by local extrusion facilities we were happy to discover the outstanding quality this company offers.
{kind=link}
{kind=link}
{kind=link}
While waiting for the extruded parts we have been playing with another new toy: the 3D printer. We have been creating prototypes of various camera models of the NC393 series. The cameras are designed and modelled in a 3D virtual environment, and can viewed and even taken apart by mouse click thanks to X3dom technology. The next step is to build actual parts on the 3D printer and physically assemble the camera prototypes, which will allow us to start using the prototypes in the physical world: finding what features are missing, and correcting and finalizing the design. For example, when the mini-panoramic NC393-4PI4 camera prototype was assembled it was clear that it needs the 4 fins (now seen on the final model) to protect the lenses from touching the surfaces as well as to provide shade from the sun. NC393-4PI4 and NC393-4PI4-IMU-GPS are small 360 degree panoramic cameras assembled with 4 fish-eye lenses especially suitable for interior panoramic applications.
The prototypes are not as slick as the actual aluminium bodies, but they give a very good example of what the actual cameras will look like.
{kind=link}
{kind=link}
{kind=link}
As of today, the 10393 and other boards are in production, the prototypes are being built and tested for design functionality, and the aluminium extrusions have been received. With all this taken care of, we are now less than one month away from the NC393 being offered for sale; the first cameras will be distributed to the loyal Elphel customers who have placed and pre-paid orders several weeks ago.
X3D assemblies from any CAD
Converting mechanical assemblies to X3D models from STEP (ISO 10303) files
Like all manufacturing companies we use mechanical CAD program to design our products. We would love to use Free Software programs for that, but so far even FreeCAD has a warning on their download page “FreeCAD is under heavy development and might not be ready for production use”. We have to use proprietary tools, our choice was the program that natively runs on GNU/Linux we use on our computers. This program generates STEP files that we can send to virtually any machine shop (locally or overseas) and expect to receive the manufactured parts that match our design. For the last 6 years we kept the CAD models for all the camera parts on Elphel Wiki hoping they might be needed not only by the machine shops we order parts from, but also by our users to incorporate (or modify) our products in their systems.
All the mechanical CAD programs can export STEP, we can use this format for assembliesThe STEP file export is quite adequate for the production, but it would be convenient for our users (including ourselves) to be able to easily navigate through the complex assemblies. Theoretically STEP can handle assemblies too, but I’ve got an impression that the CAD program owners are not that interested in the interoperability – they want everybody to use their program, and the interoperability scope is limited to a simplified scheme: CAD(their) -> CAM(any) and the assembly structure is often lost when generating output files. When we tried to export Eyesis4π camera as a STEP file it got more than 0.5GB in size and when imported (even by the same program) it resulted in over 1800 solids without any hierarchy or even the part names. Additionally the colors were lost when the STEP file was imported back and it is understandable – CAD programs need to be able to produce STEP files (otherwise they would be completely useless), but importing requirements are more relaxed. Having no control over the proprietary program output we had to find a way to use the CAM files (in STEP format) in the other way than the CAD providers intended and recreate the assembly structure ourselves.
FreeCAD as the environment for model conversionFreeCAD seemed to us as a best choice for the next step regardless to its “not ready for production” status as it has a great advantage of being FLOSS, and having excellent support for Python access to the functionality (through macros and a nice Python console). First I looked for a possibility to export data as X3D and was impressed that a FreeCAD macro that does that – export_x3d.py has less than 100 lines of code. It did not export colored faces of electronic components on the PCB, but that was something we could definitely fix ourselves.
Having working color output was a first step to a more ambitious project – feed the program with a library of STEP files of components and a flat STEP assembly file. The program should recognize each of the objects in the assembly by comparing it with the known parts, replace them with references to the library parts and provide translation and rotation. There are multiple ways how to deal with this task and I will describe what we did later in the post, in short – it just worked. We fed the program with a library of 800+ part files that we had (some custom, some just standard fasteners from McMaster), and the assembly file and it recognized almost all of the objects and correctly placed them, so Oleg Dzhimiev was able to start working on the viewer to navigate the models using the x3dom technology while I continued working on the converter.
Links to the converted modelsHere is a link to Elphel Wiki page Elphel camera assemblies. Tis page opens multiple designs – they include the new NC393 camera models (for which we do not yet received all the mechanical parts) as well as our current products for which we already had the needed CAD files.
We had not tried to convert design data exported by other mechanical CAD software and it is interesting to know if this program can help users of other CAD systems. We tried to make it agnostic to the source of the STEP files, but it does require the possibility to export files with specified color of the faces (AP214 has this possibility while AP203 does not). Color information is anyway needed as a proxy for materials/finish to distinguish between different parts that have exactly the same geometry, we also use it to hint orientation of the parts in the assembly.
There are multiple ways how the program can be improved, but at least for our project it is already usable. And we hope it is not just for us.
Technical detailsAs soon as we verified that FreeCAD can import our STEP files and it is not that difficult to generate the X3D models we started freecad_x3d project at Github. The x3d_step_assy.py macro runs in FreeCAD and generates X3D files from the STEP input, the rest of the repository is the viewer for the produced models.
Indexing the STEP part filesThe first thing the program does is it scans and indexes all the STEP models of the parts, saving the information that is needed for matching to the assembly objects. STEP opening in FreeCAD is a very slow process (especially in the GUI mode that is required to have access to the object color information), so this step is needed to significantly speed-up subsequent assembly files processing. The part invariant information such as center of gravity (center of volume to be precise) location, volume, surface area and gyration radii provided by FreeCAD. If the part has differently colored faces the centers for each color is recorded too. Additionally a list of up to 18 vertex coordinates is calculated and added – these vertices are tested to be inside (or near to) the objects in the assembly. Currently these vertices are selected as having maximal and minimal values for each of the 3 coordinates as well as their sums and differences.
Normally each part model consists of just one solid object, but in practice it is not always the case. The CAD program we use generates extra “tube” object for each thread, sometimes we do it intentionally like making a two-solid photographic UV protection filter as a frame and a glass. This allows us to selectively change solid/wireframe state when working in CAD program. Current implementation saves information about each solid in a part and places the largest (now by volume) solid first (at index 0), the matching uses only the first solid, and that leads to false-positive in reporting of the objects that do not have any matches to parts. “False” – because these unmatched objects will still appear in the X3D model as their are included in the individual part models. Removing such false positive objects from the report is definitely possible, but it was not a big hassle to manually inspect them in the FreeCAD 3D-view.
All this information is recorded in Python pickle format, one file for each STEP file. When program needs to process an assembly, it first verifies that each STEP part file has a corresponding pickle one an (re)calculates the ones that are either missing or outdated (older than the STEP model).
Generation of the X3D files for each part modelNext step after indexing of the STEP models of the parts is to generate individual parts in X3D format. Program uses the color information that exists after import in GUI mode for each object face and uses it in the generation of the X3D XML data. It wraps each object with X3D “Group” node to combine multiple possible objects in a part and to provide a bounding box information, and then adds the outmost “Transform” node with zero translation and rotation – it can be used for the viewer program to move rotate the object. Currently the viewer reads group bound box center and moves the top object in the opposite direction for convenient rotation. The imported STEP files may have large offsets of the models from the (0,0,0) point, if this is not corrected the viewer may try to rotate the object around the point that is far off-screen.
Similarly to the generation of the pickle files, program only generates part X3D models if they do not exist or are older then the input STEP files. We noticed that at this stage FreeCAD often segfaults (regardless of the version) and it seems to be related to the GUI. Luckily you only have to load this many files once, and if the FreeCAD crashes you may just restart it and the macro will continue generation of the new files.
Selection of the parts candidates for the assembly objectsOpening a complex assembly as STEP file in FreeCAD can take a while (one of our models was opening 40 minutes), so please be patient. The part matching take twice less time, so the program offers two options – use the currently active document in FreeCAD or start from the file path and open it.
When all the assembly data is available, the program indexes each object extracting parameters similar to those of the parts – volume, area, inertial properties, centers of each color (if present). Then it uses this data to create a list of parts-candidates for each assembly object, requiring that the orientation-invariant parameters of each object exported as a part of the assembly matches (to the configurable precision) that of the same part exported individually. If colors are available, the total area of each color is compared too, but match is allowed if only the shape is the same as CAD may allow to change the object color in the assembly making it different from that of the library part. If several parts match the assembly object then the better color match disqualifies other shape-only candidates, so it is possible to color-code the same-shape parts.
Matching of the assembly object to the part orientationNext step of the assembly to parts decomposition is to determine the part position and orientation to match the assembly objects. In most cases there will be no more that one candidate for each object, but if there are several the program will try them all and use the first match. It is very easy to find the translation of the part – just use the vector between the already known centers of volumes, but it is more tricky to find the correct orientation. There are multiple ways how to match orientations, and the program can be definitely improved. We chose rather simple approach that requires modification of some parts, but is rather easy as the parts models are created by us. The number of parts that required modification is rather small, this modification has to be done once per part (not for each assembly) and the modification does not invalidate the model for CAM usage.
This approach uses the offsets of the “centers of gravity” of the faces of each color (even a single-colored object may have the center of all faces offset from the center of volume) and then the principal axes of gyration that are provided by FreeCAD. Color offsets are used first, then supplemented by the gyration axes, each step verifies that the vector is non-zero and the next one is not co-linear to the first. Only two orthogonal vectors are needed, the third one needed for rotational matrix is calculated as a cross product of the first two. Use of gyration axes even if all 3 have different gyration radii ad so are reliably calculated have ambiguity as they do not provide the sign, only the line of direction. The same asymmetrical object can be oriented in 4 different ways (alternating the sign of the two of the 3 axes) and the program tries each of them. Initially I tried to compare the volume of boolean intersection of the two objects that should be the same as the volume of a single object if they match, but for some of our STEP models FreeCAD refused to calculate intersection, so I used isinside() function instead that calculates if a given point is inside the object to the certain precision so can be used to verify that all of the set of vertices saved for the part object with the transformation matrix applied end up “inside” the assembly object (actually on the border). Unfortunately even that had exception – in one of the object one vertex was returning “False” with any tolerance, even larger that the object size. In that rare case the program tries to move the test point around by the same precision-long vector, and that modification worked, FreeCAD return “True” for the isinside() call.
When the color hints are required in the part modelsUsing just the gyration principal axes fails when the object has some symmetry (point or axis). Consider a regular socket head screw. Unless it is a really short one it will have one small and two equal large gyration radii, and the axis for the small gyration radius can be reliably found (it is just the regular axis of the screw) but the two perpendicular ones are arbitrary and may be different for the part and the assembly object. That will lead that the hex head will have incorrect orientation, but usually this hex hole orientation is unimportant. So here we slightly cheated – the test vertices selected for verification with isinside() are some of the outmost ones of the solid (we selected vertices that have maximal/minimal values of each of the coordinates and sums/differences of their pairs and all three) – the hex hole does not have any of them. Most of the fasteners we use are such socket head ones, this approach would not work for hex bolts and nuts – they need to have one of the hex faces colored.
And there are other objects that require some color hints in the part model, like a square plate having no or symmetrical holes, or a turned (round) part with the symmetrical holes in it – two of the gyration radii are the same and the corresponding axes can not be unambiguously determined. You may color one of the side faces of the square faces or color the inside of a hole to break a symmetry. If the part does not have individually selectable faces in the CAD program you may create a small colored cylinder or box, align it with one of the flat faces and boolean cut it from the object, and then boolean add it to it. The result object has the same shape for CAM, but it will have a colored square or circle on one of the faces – sufficient for unambiguous definition of the orientation.
NC393 progress update: 14MPix Sensor Front End is up and running
{kind=link}
10398 Sensor Front End with 14MPix MT9F002
Sensors (ON Semiconductor MT9F002) and blank PCBs arrived in time and so I was able to hand-assemble two 10398 boards and start testing them. I had some minor problems getting data output from the first board, but it turned out to be just my bad soldering of the sensor, the second board worked immediately. To my surprise I did not have any problems with HiSPi decoder that I simulated using the sensor model I wrote myself from the documentation, so the color bar test pattern appeared almost immediately, followed by the real acquired images. I kept most of the sensor settings unmodified from the default values, just selected the correct PLL multiplier, output signal levels (1.8V HiVCM – compatible with the FPGA) and packetized format, the only other registers I had to adjust manually were exposure and color analog gains.
As it was reasonable to expect, sensitivity of the 14MPix sensor is lower than that of the 5MPix MT9P006 – our initial estimate is that it is 4 times lower, but this needs more careful measurements to find out exposure required for pixel saturation with the same illumination. Analog channel gains for both sensors we set slightly higher than minimal ones for the saturation, but such rough measurements could easily miss a factor of 1.5. MT9F002 offers more controls over the signal chain gains, but any (even analog) gain in the chain that boosts signal above the minimal needed for saturation proportionally reduces used “well capacity”, while I expect the Full Well Capacity (FWC) is already not very high for the 1.4μm x1.4 μm pixel sensor. And decrease in the number of electrons stored in a pixel accordingly increases the relative shot noise that reveals itself in the highlight areas. We will need to accurately measure FWC of the MT9F002 and have better sensitivity comparison, including that of the binned mode, but I expect to find out that 5MPix sensor are not obsolete yet and for some applications may still have advantages over the newer sensors.
{kind=link}
Image acquired with 5 MPix MT9P006 sensor, 1/2000 s
{kind=link}
Image acquired with 14MPix MT9F002 sensor, 1/500 s
Both sensors used identical f=4.5mm F3.0 lenses, the 5MPix one lens is precisely adjusted during calibration, the lens of the 14MPix sensor is just attached and focused by hand using the lens thread, no tilt correction was performed. Both images are saved at 100% JPEG quality (lossless compression) to eliminate compression artifacts, both used in-camera simple 3×3 demosaic algorithm. The 14 MPix image has visible checkerboard pattern caused by the difference of the 2 green values (green in red row, and green in the blue row). I’ll check that it is not caused by some FPGA code bug I might introduce (save as raw image and do de-bayer on a host computer), but it may also be caused by pixel cross-talk in the sensor. In any case it is possible to compensate or at least significantly reduce in the output data.
MT9F002 transmits data over 5 differential 100Ω pairs: 1 clock pair and 4 data lanes. For the initial tests I used our regular 70mm flex cable used for the parallel interface sensors, and just soldered 5 of 100Ω resistors to the contacts at the camera side end. It did work and I did not even have to do any timing adjustments of the differential lanes. We’ll do such adjustments in the future to get to the centers of the data windows – both the sensor and the FPGA code have provisions for that. The physical 100Ω load resistors were needed as it turned out that Xilinx Zynq has on-chip differential termination only for the 2.5V (or higher) supply voltages on the regular (not “high performance”) I/Os and this application uses 1.8V interface power – I missed this part of documentation and assumed that all the differential inputs have possibility to turn on differential termination. 660 Mbps/lane data rate is not too high and I expect that it will be possible to use short cables with no load resistors at all, adding such resistors to the 10393 board is not an option as it has to work with both serial and parallel sensor interfaces. Simultaneously we designed and placed an order for dedicated flex cables 150mm long, if that will work out we’ll try longer (450mm) controlled impedance cables.
NC393 progress update: one gigapixel per second (12x faster than NC353)
All the PCBs for the new camera: 10393, 10389 and 10385 are modified to rev “A”, we already received the new boards from the factory and now are waiting for the first production batch to be build. The PCB changes are minor, just moving connectors away from the board edge to simplify mechanical design and improve thermal contact of the heat sink plate to the camera body. Additionally the 10389A got m2 connector instead of the mSATA to accommodate modern SSD.
While waiting for the production we designed a new sensor board (10398) that has exactly the same dimensions, same image sensor format as the current 10338E and so it is compatible with the hardware for the calibrated sensor front ends we use in photogrammetric cameras. The difference is that this MT9F002 is a 14 MPix device and has high-speed serial interface instead of the legacy parallel one. We expect to get the new boards and the sensors next week and will immediately start working with this new hardware.
In preparation for the faster sensors I started to work on the FPGA code to make it ready for the new devices. We planned to use modern sensors with the serial interfaces from the very beginning of the new camera design, so the hardware accommodates up to 8 differential data lanes plus a clock pair in addition to the I²C and several control signals. One obviously required part is the support for Aptina HiSPi (High Speed Serial Pixel) interface that in case of MT9F002 uses 4 differential data lanes, each running at 660 Mbps – in 12-bit mode that corresponds to 220 MPix/s. Until we’ll get the actual sensors I could only simulate receiving of the HiSPi data using the sensor model written ourselves following the interface documentation. I’ll need yet to make sure I understood the documentation correctly and the sensor will produce output similar to what we modeled.
The sensor interface is not the only piece of the code that needed changes, I also had to increase significantly the bandwidth of the FPGA signal processing and to modify the I²C sequencer to support 2-byte register addresses.
Data that FPGA receives from the sensor passes through the several clock domains until it is stored in the system memory as a sequence of compressed JPEG/JP4 frames:
- Sensor data in each channel enters FPGA at a pixel clock rate, and subsequently passes through vignetting correction/scaling module, gamma conversion module and histogram calculation modules. This chain output is buffered before crossing to the memory clock domain.
- Multichannel DDR3 memory controller records sensor data in line-scan order and later retrieves it in overlapping (for JPEG) or non-overlapping (for JP4) square tiles.
- Data tiles retrieved from the external DDR3 memory are sent to the compressor clock domain to be processed with JPEG algorithm. In color JPEG mode compressor bandwidth has to be 1.5 higher than the pixel rate, as for 4:2:0 encoding each 16×16 pixels macroblock generate 6 of the 8×8 image blocks – 4 for Y (intensity) and 2 – for color components. In JP4 mode when the de-mosaic algorithm runs on the host computer the compressor clock rate equals the pixel rate.
- Last clock domain is 150MHz used by the AXI interface that operates in 64-bit parallel mode and transfers the compressed data to the system memory.
Two of these domains used double clock rate for some of the processing stages – histograms calculation in the pixel clock domain and Huffman encoder/bit stuffer in the compressor. In the previous NC353 camera pixel clock rate was 96MHz (192 MHz for double rate) and compressor rate was 80MHz (160MHz for double rate). The sensor/compressor clock rates difference reflects the fact that the sensor data output is not uniform (it pauses during inactive lines) and the compressor can process the frame at a steady rate.
MT9F002 image sensor has the output pixel rate of 220MPix/s with the average (over the full frame) rate of 198MPix/s. Using double rate clocks (440MHz for the sensor channel and 400MHz for the compressor) would be rather difficult on Zynq, so I needed first to eliminate such clocks in the design. It was possible to implement and test this modification with the existing sensor, and now it is done – four of the camera compressors each run at 250 MHz (even on “-1″, or “slow” speed grade silicon) making it total of 1GPix/sec. It does not need to have 4 separate sensors running simultaneously – a single high speed imager can provide data for all 4 compressors, each processing every 4-th frame as each image is processed independently.
At this time the memory controller will be a bottleneck when running all four MT9F002 sensors simultaneously as it currently provides only 1600MB/s bandwidth that may be marginally sufficient for four MT9F002 sensor channels and 4 compressor channels each requiring 200MB/s (bandwidth overhead is just a few percent). I am sure it will be possible to optimize the memory controller code to run at higher rate to match the compressors. We already identified which parts of the memory controller need to be modified to support 1.5x clock increase to the total of 2400MB/s. And as the production NC393 camera will have higher speed grade SoC there will be an extra 20% performance increase for the same code. That will provide bandwidth sufficient not just to run 4 sensors at full speed and compress the output data, but to do some other image manipulation at the same time.
Compared to the previous Elphel NC353 camera the new NC393 prototype already is tested to have 12x higher compressor bandwidth (4 channels instead of one and 250MPix/s instead of 80MPix/s), we plan to have the actual sensor with a full data processing chain results soon.
Google is testing AI to respond to privacy requests
Robotic customer support fails while pretending to be an outsourced human. Last week I searched with Google for Elphel and I got a wrong spelled name, wrong address and a wrong phone number.
{kind=link}
Google search for Elphel
A week ago I tried Google Search for our company (usually I only check recent results using last week or last 3 days search) and noticed that on the first result page there is a Street View of my private residence, my home address pointing to a business with the name “El Phel, Inc”.
Yes, when we first registered Elphel in 2001 we used our home address, and even the first $30K check from Google for development of the Google Books camera came to this address, but it was never “El Phel, Inc.” Later wire transfers with payments to us for Google Books cameras as well as Street View ones were coming to a different address – 1405 W. 2200 S., Suite 205, West Valley City, Utah 84119. In 2012 we moved to the new building at 1455 W. 2200 S. as the old place was not big enough for the panoramic camera calibration.
I was not happy to see my house showing as the top result when searching for Elphel, it is both breach of my family privacy and it is making harm to Elphel business. Personally I would not consider a 14-year old company with international customer base a serious one if it is just a one-man home-based business. Sure you can get the similar Street View results for Google itself but it would not come out when you search for “Google”. Neither it would return wrongly spelled business name like “Goo & Gel, Inc.” and a phone number that belongs to a Baptist church in Lehi, Utah (update: they changed the phone number to the one of Elphel).
Google original location
Honestly there was some of our fault too, I’ve seen “El Phel” in a local Yellow Pages, but as we do not have a local business I did not pay attention to that – Google was always good at providing relevant information in the search results, extracting actual contact information from the company “Contacts” page directly.
Noticing that Google had lost its edge in providing search results (Bing and Yahoo show relevant data), I first contacted Yellow Pages and asked them to correct information as there is no “El Phel, Inc.” at my home address and that I’m not selling any X-Ray equipment there. They did it very promptly and the probable source of the Google misinformation (“probable” as Google does not provide any links to the source) was gone for good.
I waited for 24 hours hoping that Google will correct the information automatically (post on Elphel blog appears in Google search results in 10 – 19 seconds after I press “Publish” button). Nothing happened – same “El Phel, Inc.” in our house.
So I tried to contact Google. As Google did not provide source of the search result, I tried to follow recommendations to correct information on the map. And the first step was to log in with Google account, since I could not find a way how to contact Google without such account. Yes, I do have one – I used Gmail when Google was our customer, and when I later switched to other provider (I prefer to use only one service per company, and I selected to use Google Search) I did not delete the Gmail account. I found my password and was able to log in.
First I tried to select “Place doesn’t exist” (There is no such company as “El Phel, Inc.” with invalid phone number, and there is no business at my home address).
Auto confirmation came immediately:
From: Google Maps <noreply-maps-issues@google.com>
Date: Wed, Sep 23, 2015 at 9:55 AM
Subject: Thanks for the edit to El Phel Inc
To: еlphеl@gmаil.cоm
Maps
Thank you
Your edit is being reviewed. Thanks for sharing your knowledge of El Phel Inc.
El Phel Inc
3200 Elmer St, Magna, UT, United States
Your edit
Place doesn't exist
Edited on Sep 23, 2015 · In review
Keep exploring,
The Google Maps team
© 2015 Google Inc. 1600 Amphitheatre Parkway, Mountain View, CA 94043
You've received this confirmation email to update you about your editing activities on Google Maps.
But nothing happened. Two days later I tried with different option (there was no place to provide text entry)
Your edit
Place is private
No results either.
Then I tried to follow the other link after the inappropriate search result – “Are you the business owner?” (I’m not at owner of the non-existing business, but I am an owner of my house). And yes, I had to use my Gmail account again. There were several options how I prefer to be contacted – I selected “by phone”, and shortly after a female-voiced robot called. I do not have a habit of talking to robots, so I did not listen what it said waiting for keywords like: “press 0 to talk to a representative” or “Please stay on the line…”, but it never said anything like this and immediately hang up.
Second time I selected email contact, but it seems to me that the email conversation was with some kind of Google Eliza. This was the first email:
From : local-help@google.com
To : andrey@elphel.com
Subject : RE: [7-2344000008781] Google Local Help
Date : Thu, 24 Sep 2015 22:48:47 -0700
Add Label
Hi,
Greetings from Google.
After investigating, i found that here is an existing page on Google (El Phel Inc-3200 S Elmer St Magna, UT 84044) which according to your email is incorrect information.
Apologies for the inconvenience andrey, however as i can see that you have created a page for El Phel Inc, hence i would first request you to delete the Business page if you aren't running any Business. Also you can report a problem for incorrect information on Maps,Here is an article that would provide you further clarity on how to report a problem or fix the map.
In case you have any questions feel free to reply back on the same email address and i would get back to you.
Regards,
Rohit
Google My Business Support.
This robot tried to mimic a kids language (without capitalizing “I” and the first letter of my name), and the level of understanding the matter was below that of a human (it was Google, not me who created that page, I just wanted it to be removed).
I replied as I thought it still might be a human, just tired and overwhelmed by so many privacy-related requests they receive (the email came well after hours in United States).
From : andrey <andrey@elphel.com>
To : local-help@google.com
Subject : RE: [7-2344000008781] Google Local Help
Date : Fri, 25 Sep 2015 00:16:21 -0700
Hello Rohit,
I never created such page. I just tried different ways to contact Google to remove this embarrassing link. I did click on "Are you the business owner" (I am the owner of this residence at 3200 S Elmer St Magna, UT 84044) as I hoped that when I'll get the confirmation postcard I'll be able to reply that there is no business at this residential address).
I did try link "how to report a problem or fix the map", but I could not find a relevant method to remove a search result that does not reference external page as a source, and assigns my home residence to the search results of the company, that has a different (than listed) name, is located in a different city (West Valley City, 84119, not in Magna, 84044), and has a different phone number.
So please, can you remove that incorrect information?
Andrey Filippov
Nothing happened either, then on Sunday night (local time) came another email from “Rohit”:
From : local-help@google.com
To : andrey@elphel.com
Subject : RE: [7-2344000008781] Google Local Help
Date : Sun, 27 Sep 2015 18:11:44 -0700
Hi,
Greetings from Google.
I am working on your Business pages and would let you know once get any update.
Please reply back on the same email address in case of any concerns.
Regards,
Rohit
Google My Business Support
You may notice that it had the same ticket number, so the sender had all the previous information when replying. For any human capable of using just Google Search it would be not more than 15-30 seconds to find out that their information is incorrect and either remove it completely (as I asked) or replace with some relevant one.
And there is another detail that troubles me. Looking at the time/days when the “Google My Business Support” emails came, and the name “Rohit” it may look like it came from India. While testing a non-human communications Google might hope that correspondents would more likely attribute some inconsistencies in the generated emails to the cultural differences and miss actual software flaws. Does Google count on us being somewhat racists?
Following provided links I was not able to get any response from a human representative, only two robots (phone and email) contacted me. I hope that this post will work better and help to cure this breach of my family privacy and end harm this invalid information provided by a so respected Internet search company causes to the business. I realize that robots will take over more and more of our activities (and we are helping that to happen ourselves), but maybe this process sometimes goes too fast?
NC393 progress update: all hardware is operational
{kind=link}
10393 with 4 image sensors
Finally all the parts of the NC393 prototype are tested and we now can make the circuit diagram, parts list and PCB layout of this board public. About the half of the board components were tested immediately when the prototype was built – it was almost two years ago – those tests did not require any FPGA code, just the initial software that was mostly already available from the distributions for the other boards based on the same Xilinx Zynq SoC. The only missing parts were the GPL-licensed initial bootloader and a few device drivers.
Implementation of the 16-channel DDR3 memory controller
Getting to the next part – testing of the FPGA-controlled DDR3 memory took us longer: the overall concept and the physical layer were implemented in June 2014, timing calibration software and application modules for image image recording and retrieval were implemented in the spring of 2015.
Initial image acquisition and compressionWhen the memory was proved operational what remained untested on the board were the sensor connections and the high speed serial links for SATA. I decided not to make any temporary modules just to check the sensor physical connections but to port the complete functionality of the image acquisition, processing and compression of the existing NC353 camera (just at a higher clock rate and multiple channels instead of a single one) and then test the physical operation together with all the code.
Sensor acquisition channels: From the sensor interface to the video memory bufferThe image acquisition code was ported (or re-written) in June, 2015. This code includes:
- Sensor physical interface – currently for the existing 10338 12-bit parallel sensor front ends, with provisions for the up to 8-lanes + clock high speed serial sensors to be added. It is also planned to bond together multiple sensor channels to interface single large/high speed sensor
- Data and clock synchronization, flexible phase adjustment to recover image data and frame format for different camera configurations, including sensor multiplexers such as the 10359 board
- Correction of the lens vignetting and fine-step scaling of the pixel values, individual for each of the multiplexed sensors and color channel
- Programmable gamma-conversion of the image data
- Writing image data to the DDR3 image buffer memory using one or several frame buffers per channel, both 8bpp and 16bpp (raw image data, bypassing gamma-conversion) formats are supported
- Calculation of the histograms, individual for each color component and multiplexed sensor
- Histograms multiplexer and AXI interface to automatically transfer histogram data to the system memory
- I²c sequencer controls image sensors over i²c interface by applying software-provided register changes when the designated frame starts, commands can be scheduled up to 14 frames in advance
- Command frame sequencer (one per each sensor channel) schedules and applies system register writes (such as to control compressors) synchronously to the sensors frames, commands can be scheduled up to 14 frames in advance
Image compressors get the input data from the external video buffer memory organized as 16×16 pixel macroblocks, in the case of color JPEG images larger overlapping tiles of 18×18 (or 20×20) pixels are needed to interpolate “missing” colors from the input Bayer mosaic input. As all the data goes through the buffer there is no strict requirement to have the same number of compressor and image acquisition modules, but the initial implementation uses 1:1 ratio and there are 4 identical compressor modules instantiated in the design. The compressor output data is multiplexed between the channels and then transferred to the system memory using 1 or 2 of Xilinx Zynq AXI HP interfaces.
This portion of the code is also based on the earlier design used in the existing NC353 camera (some modules are reusing code from as early as 2002), the new part of the code was dealing with a flexible memory access, older cameras firmware used hard-wired 20×20 pixel tiles format. Current code contains four identical compressor channels providing JPEG/JP4 compression of the data stored in the dedicated DDR3 video buffer memory and then transferring result to the system memory circular buffers over one or two of the Xilinx Zynq four AXI HP channels. Other camera applications that use sensor data for realtime processing rather than transferring all the image data to the host may reduce number of the compressors. It is also possible to use multiple compressors to work on a single high resolution/high frame rate sensor data stream.
Single compressor channel contains:
- Macroblock buffer interface requests 32×18 or 32×16 pixel tiles from the memory and provides 18×18 overlapping macroblocks for JPEG or 16×16 non-overlapping macroblocks for JP4 using 4KB memory buffer. This buffer eliminates the need to re-read horizontally overlapping pixels when processing consecutive macroblocks
- Pixel buffer interface retrieves data from the memory buffer providing sequential pixel stream of 18×18 (16×16) each macroblock
- Color conversion module selects one of the sub-modules : csconvert18a, csconvert_mono, csconvert_jp4 or csconvertjp4_diff to convert possibly overlapping Bayer mosaic tiles to a sequence of 8×8 blocks for 2-d DCT transform
- Average value extractor calculates average value in each 8×8 block, subtracts it before DCT and restores after – that reduces data width in DCT processing module
- xdct393 performs 2-d DCT for each 8×8 pixel block
- Quantizer re-orders each block DCT components from the scan-line to zigzag sequence and quantizes them using software-calculated and loaded tables. This is the only lossy stage of the JPEG algorithm, when the compression quality is set to 100% all the coefficients are set to 1 and the conversion is lossless
- Focus sharpness module accumulates amount of high-frequency components to estimate image sharpness over specified window to facilitate (auto) focusing. It also allows to replace on-the-fly average block value of the image with amount of the high frequency components in the same blog, providing visual indication of the focus sharpness
- RLL encoder converts the continuous 64 samples/per block data stream in to RLL-encoded data bursts
- Huffman encoder uses software-generated tables to provide additional lossless compression of the RLL-encoded data. This module (together with the next one) runs and double pixel clock rate and has an input FIFO between the clock domains
- Bit stuffer consolidates variable length codes coming out from the Huffman encoder into fixed-width words, escaping each 0xff byte (these bytes have special meaning in JPEG stream) by inserting 0×00 right after it. It additionally provides image timestamp and length in bytes after the end of the compressed data before padding the data to multiple of 32-byte chunks, this metadata has fixed offset before the 32-byte aligned data end
- Compressor output FIFO converts 16-bit wide data from the bit stuffer module received at a double compressor clock rate (currently 200MHz) and provides 64-bit wide output at the maximal clock rate (150MHz) for AXI HP port of Xilinx Zynq, it also provides buffering when several compressor channels share the same AXI HP channel
Another module – 4:1 compressor multiplexer is shared between multiple compressor channels. It is possible (defined by Verilog parameters) to use either single multiplexer with one AXI HP port (SAXIHP1) and 4 compressor inputs (4:1), or two of these modules interfacing two AXI HP channels (SAXIHP1 and SAXIHP2), reducing number of concurrent inputs of each multiplexer to just 2 (2 × 2:1). Multiplexers use fair arbitration policy and consolidate AXI bursts to full 16×64bits when possible. Status registers provide image data pointers for last write and last frame start, each as sent to AXI and after confirmation using AXI write response channel.
Porting remaining FPGA functionality to the new cameraAdditional modules where ported to complete the existing NC353 functionality:
- Camera real time clock that provides current time with 1 microsecond resolution to various modules. It has accumulator-based correction circuitry to compensate for crystal oscillator frequency variations
- Inter-camera synchronization module generates and/or receives synchronization signals between multiple camera modules or other devices. When used between the cameras, each synchronization pulse has a timestamp information attached in a serialized form, so multiple synchronized cameras have all the simultaneous images metadata contain the same time code generated by the “master” camera
- Event logger records data from multiple sources, such as GPS, IMU, image acquisition events and external signal channel (like a vehicle wheel rotation sensor)
All that code was written (either new or modified from the existing NC353 FPGA project by the end of July, 2015 and then the most fun began. First I used the proven NC353 code to simulate (using Icarus Verilog + GtkWave) with the same input data as the one provided to the new x393 code, following the signal chains and making sure that each checkpoint data matched. That was especially useful when debugging JPEG compressor, as the intermediate data is difficult to follow. When I was developing the first JPEG compressor in 2002 I had to save output data from the various processing stages and compare it to the software compression output of the same image data from the similar stages. Having working implementation helped a lot and in 3 weeks I was able to match the output from all the processing stages described above except the event logger that I did not verify yet.
Testing the hardwareThen it was the time for translating the Verilog test fixture code to the Python programs running on the target hardware extending the code developed earlier for the memory controller. The code is able to parse Verilog parameter definition files – that simplified synchronization of the Verilog and Python code. It would be nice to use something like Cocotb in the future and completely get rid of the Verilog to Python manual translation.
As I am designing code for the reconfigurable FPGA (not for ASIC) my usual strategy is not to get high simulation coverage, but to simulate to a “barely working” stage, then use the actual hardware (that runs tens of millions times faster than the simulator), detect the problems and then try to achieve the same condition with the simulation. But when I just started to run the hardware I realized that there is too little I can get about the current state of the hardware. Remembering about the mess of the temporary debug code I had in the previous projects and the inability of the synthesis tool to directly access the qualified names of the signals inside sub-modules, I implemented rather simple debug infrastructure that uses a single register ring (like a simplified JTAG) through all the modules to debug and a matching Python code that allows access to individual bit fields of the ring. Design includes a single debug_master and debug_slave modules in each of the design module instances that needs debugging (and the modules above – up to the top one). By the time the camera was able to generate correct images the total debug ring consisted of almost a hundred of the 32-bit registers, when I later disabled this debug functionality by commenting out a single `define DEBUB_RING macro it recovered almost 5% of the device slices. The program output looks like:
x393 +0.001s--> print_debug 0x38 0x3e
038.00: compressors393_i.jp_channel0_i.debug_fifo_in [32] = 0x6e280 (451200)
039.00: compressors393_i.jp_channel0_i.debug_fifo_out [28] = 0x1b8a0 (112800)
039.1c: compressors393_i.jp_channel0_i.dbg_block_mem_ra [ 3] = 0x3 (3)
039.1f: compressors393_i.jp_channel0_i.dbg_comp_lastinmbo [ 1] = 0x1 (1)
03a.00: compressors393_i.jp_channel0_i.pages_requested [16] = 0x26c2 (9922)
03a.10: compressors393_i.jp_channel0_i.pages_got [16] = 0x26c2 (9922)
03b.00: compressors393_i.jp_channel0_i.pre_start_cntr [16] = 0x4c92 (19602)
03b.10: compressors393_i.jp_channel0_i.pre_end_cntr [16] = 0x4c92 (19602)
03c.00: compressors393_i.jp_channel0_i.page_requests [16] = 0x4c92 (19602)
03c.10: compressors393_i.jp_channel0_i.pages_needed [16] = 0x26c2 (9922)
03d.00: compressors393_i.jp_channel0_i.dbg_stb_cntr [16] = 0xcb6c (52076)
03d.10: compressors393_i.jp_channel0_i.dbg_zds_cntr [16] = 0xcb6c (52076)
03e.00: compressors393_i.jp_channel0_i.dbg_block_mem_wa [ 3] = 0x4 (4)
03e.03: compressors393_i.jp_channel0_i.dbg_block_mem_wa_save [ 3] = 0x0 (0)
All the problems I encountered while trying to make hardware work turned out to be reproducible (but no always easy) with the simulation and the next 3 weeks I was eliminating then one by one. When I’ve got to the 51-st version of the FPGA bitstream file (there were several more when I forgot to increment version number) camera started to produce consistently valid JPEG files.
{kind=link}
First 4-sensor image acquired with NC393 camera
At that point I replaced a single sensor front end with no lens attached (just half of the input sensor window was covered with a tape to produce a blurry shadow in the images) with four complete SFE with lenses simultaneously using a piece of Eyesis4π hardware to point the individual sensors at the 45° angles (in portrait mode) covering 180°×60° FOV combined – it resulted in the images shown above. Sensor color gains are not calibrated (so there is visible color mismatch) and the images are not stitched together (just placed side-by-side) but i consider it to be a significant milestone in the NC393 camera development.
SATA controller statusAlmost at the same time Alexey who is working on SATA controller for the camera achieved an important milestone too. His code running in Xilinx Zynq was able to negotiate and establish link with an mSATA SSD connected to the NC393 prototype. There is still a fair amount of design work ahead until we’ll be able to use this controller with the camera, but at least the hardware operation of this part of the design is verified now too.
What is nextHaving all the hardware on the 10393 verified we are now able to implement minor improvements and corrections to the 3 existing boards of the NC393 camera:
- 10393 itself
- 10389 – extension board with mSATA SSD, eSATA/USB combo connector, micro-USB and synchronization I/O
- 10385 – power supply board
And then make the first batch of the new cameras that will be available for other developers and customers.
We also plane to make a new sensor board with On Semiconductor (former Aptina, former Micron) MT9F002 – 14MPix sensor with the same 1/2.3″ image format as the MT9F006 used with the current NC353 cameras. This 12-bit sensor will allow us to try multi-lane high speed serial interface keeping the same physical dimension of the sensor board and use the same lenses as we use now.
NC393 progress update and a second life of the NC353 FPGA code
Another update on the development of the NC393 camera: finished adding FPGA code that re-implements functionality of the NC353 camera (just with additional multi-sensor capability), including JPEG/JP4 compressors, IMU/GPS logger and inter-camera synchronization. Next step – simulation and debugging, and it will use co-simulating of the same sensor image data using the code of the existing NC353 camera. This involves updating of that camera code to the state compatible with the development tools we use, and so the additional sub-project was spawned.
Verilog code development with VDT plugin for Eclipse IDE
Before describing the renovation of the NC353 camera FPGA code I need to tell about the software we use for the last year. Living in the world where FPGA chip manufactures have monopoly (or duopoly as there are 2 major players) on the rather poor software tools, I realize that this will not change in the short term. But it is possible to constrain those proprietary creations in the designated “cages” letting them do only certain tasks that require secret knowledge of the chip internals, but do not let them take control of the whole development process, depend on them abandoning one software environment and introducing another half-made one as soon as you’ll get used to the previous.
This is what VDT is about – it uses one of the most standard development environments – Eclipse IDE, combines it with a heavily modified version of VEditor and the Tool Specification Language that allows developers to integrate additional tools without getting inside the plugin code itself. Integration involves writing tool descriptions in TSL (this work is based on the tool manufacturer manual that specifies command options and parameters) and possibly creating custom parsers for the tool output – these programs may be written in any programming language developer is comfortable with.
Current integration includes the Free Software simulation programs (such as Icarus Verilog with GtkWave). As it is safe to rely on the Free Software we may add code specific to these programs in the plugin body to have deeper integration and combine code and waveforms navigation, breakpoints support.
For the FPGA synthesis and implementation tools this software supports Xilinx ISE and Vivado, we are now working on Altera Quartus too. There is no VDT code dependence on the specifics of each of these tools, and the tools are connected to the IDE using ssh and rsync, so they do not have to run on the same workstation.
Renovating the NC353 camera codeInitially I just planned to enter the NC353 camera FPGA code into VDT environment for simulation. When I opened it in this IDE it showed more than 200 warnings in the code. Most were just unused wires/registers and signal width mismatch that did not impact the functioning of the camera, but at least one was definitely a bug – a one that gets control in very rare occasions and so is difficult to catch.
When I fixed most of these warnings and made sure simulation works, I decided to try to run ISE 14.7 tools and generate a functional bitstream. There were multiple incompatibilities between ISE 10 (which was last used to generate a bitstream) and the current version – most modifications were needed to change description of the I/O standard and other parameters of the device pins (from constraint file and “// synthesis attribute …” in the code to modern style of using parameters.
That turned out to be doable – first I made the design agree with all the tools to the very last (bitstream generation), then reconciled the generated pad report with the one generated with old tools (there are still some differences remaining but they are understandable and OK). Finally I had to figure out that I need to turn on non-default option to use timing constraints and how to change the speed grade to match the one used with the old tools, and that resulted in a bitstream file that I tested on just one camera and got images. It was a second attempt – the first one resulted in a “kernel panic” and I had to reflash the camera. The project repository has the detailed description how to make such testing safe, but it is still better to try using your modified FPGA code only if you know how to “unbrick” the camera.
We’ll do more testing of the bit files generated by the ISE 14.7, but for now we need to focus on the NC393 development and use NC393 code as a reference for simulation.
Back to NC393Before writing simulation test code for the NC393 camera, I made the code to pass all the Vivado tools and result in a bitfile. That required some code tweaking, but finally it worked. Of course there will be some code change to fix bugs revealed during verification, but most likely changes will not be radical. This assumption allows to see the overall device utilization and confirm that the final design is going to fit.
Table 1. NC393 FPGA Resources Utilization Type Used Available Utilization(%) Slice 14222 19650 72.38 LUT as Logic 31448 78600 40.01 LUT as Memory 1969 26600 7.40 LUT Flip Flop Pairs 44868 78600 57.08 Block RAM Tile 78.5 265 29.62 DSPs 60 400 15.00 Bonded IOB 152 163 93.25 IDELAYCTRL 3 5 60.00 IDELAYE2/IDELAYE2_FINEDELAY 78 250 31.20 ODELAYE2/ODELAYE2_FINEDELAY 43 150 28.67 ILOGIC 72 163 44.17 OLOGIC 48 163 29.45 BUFGCTRL 16 32 50.00 BUFIO 1 20 5.00 MMCME2_ADV 5 5 100.00 PLLE2_ADV 5 5 100.00 BUFR 8 20 40.00 MAXI_GP 1 2 50.00 SAXI_GP 2 2 100.00 AXI_HP 3 4 75.00 AXI_ACP 0 1 0.00One AXI general purpose master port (MAXI_GP) and one AXI “high performance” 64-bit slave port are reserved for the SATA controller, and the 64-bit cache-coherent port (AXI_ACP) will be used for CPU accelerators for the multi-sensor image processing.
Next development step will be simulation and debugging of the project code, and luckily large part of the code can be verified by comparing with the older NC353
GTX_GPL – Free Software Verilog module to simulate a proprietary FPGA primitive
Widespread high-speed protocols, which are based on serial interfaces, have become easier and easier to implement on FPGAs. If you take a look at Xilinx’s chips series, you can monitor an evolution of embedded transceivers from some awkwardly inflexible models to much more compatible ones. Nowadays even the affordable 7 series FPGAs possess GTX transceivers. Basically, they represent a unification of various protocols phy-levels, where the versatility is provided by parameters and control input signals.
The problem is, for some reason GTX’s simulation model is a secured IP block. It means that without proprietary software it’s impossible to compile and simulate the transceiver. Moreover, we use Icarus Verilog for these purposes, which doesn’t provide deciphering capabilities for now, and doesn’t seem to ever be able to do so: http://sourceforge.net/p/iverilog/feature-requests/35/
Still, our NC393 camera has to use GTX as a part of SATA host controller design. That’s why it was decided to create a small simulation model, which shall behave as GTX, at least within some limitation and assumption. This was done so that we could create a full-fledged non-synthesizable verification environment and provide our customers with a universal within simulation purposes solution.
The project itself can be found at github. The implementation is still crude and contains only the bare minimum required to achieve our goals. However, it assumes a possibility to be broadened onto another protocol’s case. That’s why it preserves the original GTX structure, as it’s presented in Xilinx’s “7 Series FPGAs GTX/GTH Transceivers User Guide v1.11″, also known as UG476: http://www.xilinx.com/support/documentation/user_guides/ug476_7Series_Transceivers.pdf
The overall design of the so called GTX_GPL is split into 4 parts, contained in a wrapper to ensure interface compatibility with the original GTX. These parts are: TX – transmitter, RX – receiver, channel clocking and common clocking.
All of the clocking scheme was based on an assumption of clocks, PLLs, and interconnects being ideal, so no setup/hold violation/metastability are expected. That itself makes the design non-synthesizable, but greatly reduces its complexity.
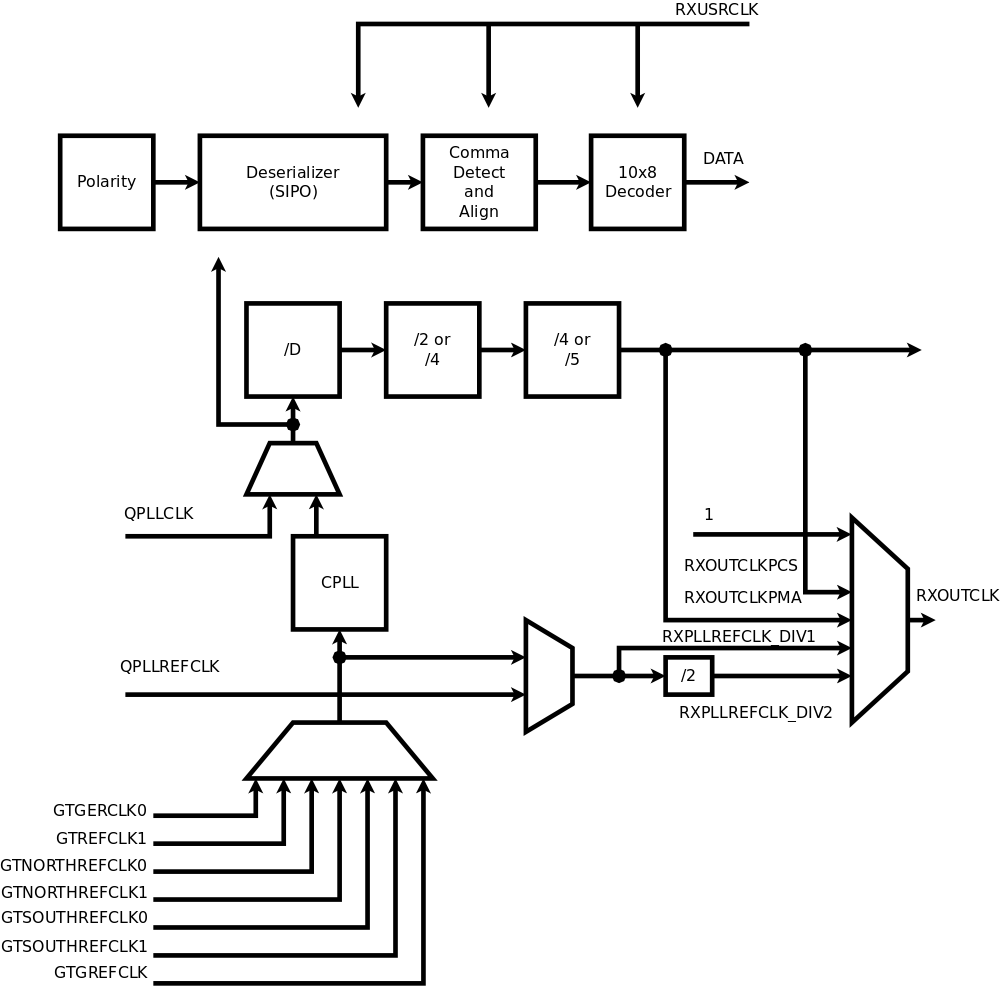{kind=link}
Receiver + Clocking
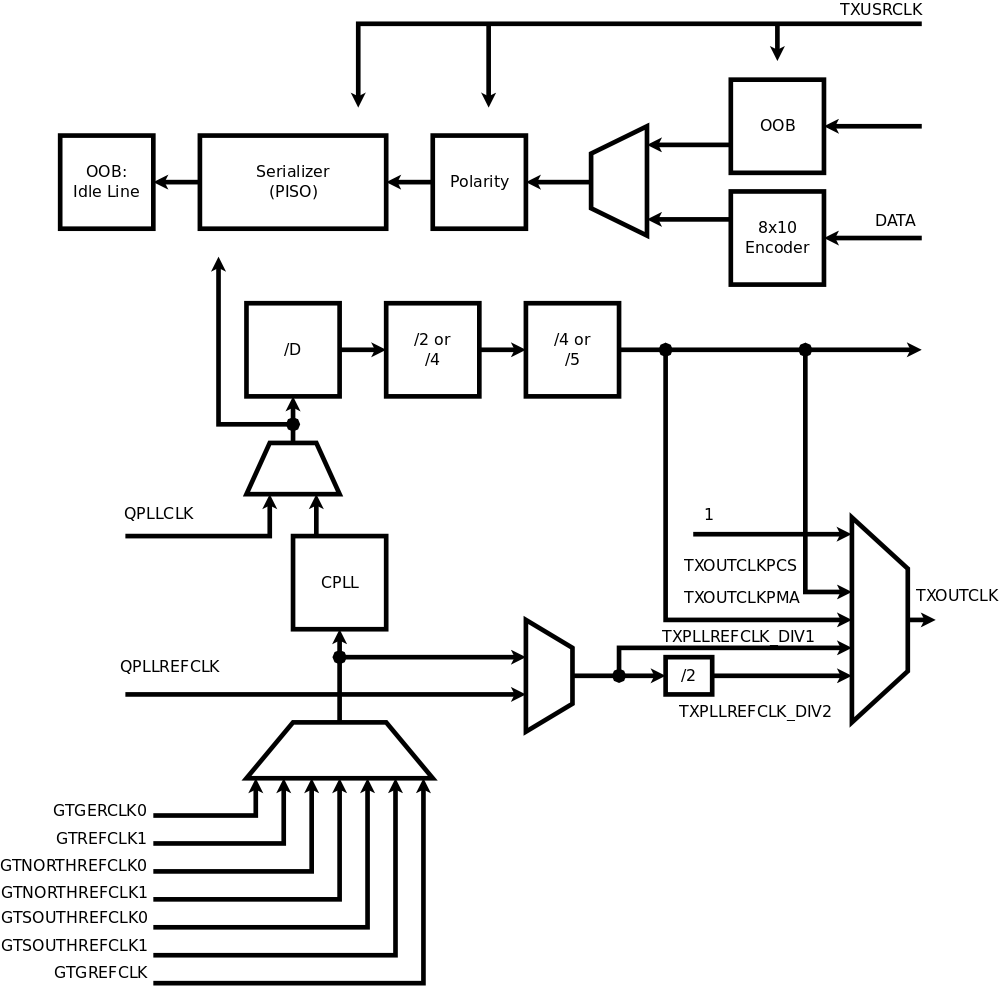{kind=link}
Transmitter + Clocking
Transmitter and receiver schemes are presented in the figures. Each is provided with a clocking mechanism. You can compare it to GTX’s corresponding schemes (see UG476, pages 107, 133, 149, 169). As you can see, TX and RX lack the original functional blocks. However, many of them are important only for synthesis or precise post-synthesis simulation, like phase adjustments or analog-level blocks. Some of them (like the gearbox) are excessive for SATA and implementing them can be costly.
Despite all of that, current implementation passes some basic tests when SATA parameters are turned on. Resulting waves were compared to ones received by swapping GTX_GPL with the original GTX_CHANNEL primitive as a device-under-test, and they showed more or less the same behavior.
You can access to a current version via github. It’s not necessary to clone or download the whole repository, but enough to acquire ‘GTXE2_CHANNEL.v’ file from there. This file represents a collection of all necessary modules from the repository, with GTXE2_CHANNEL as a top. After including (or linking as a lib file/source file) it in your project, the original unisims primitive GTXE2_CHANNEL.v will be overridden.
If you find some bugs during simulation in SATA context or you want some features to be implemented (within any protocol’s set-up), feel free to leave a message via comments, PM or github.
Overall, the design shall be useful for verification purposes. It allows to create a proper GPL licensed simulation verification environment which is not hard-bound to a proprietary software.
NC393 progress update: HDL code for sensor channels is ported or re-written
Quick update: a new chunk of code is added to the NC393 camera FPGA project. It is a second (of three needed to match the existing NC353 functionality) major parts of the system after the memory controller is finished. This code is just written, it still has to be verified by the simulation first, and then by synthesizing and by running it on the actual hardware. We plan to do that when the third part – image compressors will be ported to the new system too. The added code deals with receiving data from the image sensors and pre-processing it before storing in the video memory. FPGA-based systems are very flexible and many other configurations like support of multi-lane serial interface sensors or using several camera ports to connect a single large high-speed sensor are possible and will be implemented later. The table below summarizes parameters of the current code only.
Table 1. NC393 Sensor Connections and Pre-processing
Feature
Value
Number of sensor ports
4
Total number of multiplexed sensors
16
Total number of multiplexed sensors with existing 10359 multiplexer board
12
Sensor interface type (implemented in HDL)
parallel 12 bits
Sensor interface hardware compatibility
parallel LVCMOS/serial differential 8 lanes + clock
Sensor interface voltage levels
programmable up to 3.3V
Number of I²C sequencers
4 (1 per port)
Number of I²C sequencers frames
16
Number of I²C sequencers commands per frame
64
I²C sequencers commands data width
16/8 bits
Image data width stored
16/8 bits per pixel
Gamma conversion regions per port
4
Histograms: number of rectangular ROI (Regions of Interest) per port
4
Histograms: number of color channels
4
Histograms: number of bins per color
256
Histograms: width per bin
18 or 32 bits
Histograms: number of histograms stored per sensor
16
Up to 4 sensor channel modules can be instantiated in the camera, one per each of the sensor ports. In most applications all ports will run at the same clock frequency, but each of them can use a different clock and so heterogeneous sensors can be attached if needed. Current modules support 12 bit parallel data (such as Aptina MT9P006 we currently use), 8-lane+clock serial differential interface will be added later.
Sensor modules include programmable delay elements on each input line to optimize sampling of the data and a small FIFO to compensate for the phase variations between the system free running clocks and the sensor output clocks influenced by the sensors and optional multiplexer PLLs.
Similarly to the NC353 sensor modules contain dedicated I²C sequencers. These sequencers allow to synchronize I²C commands sent to the sensors with the sensor frame sync signals, they also reduce response time requirements to the software – the commands to be issued can be scheduled ahead of time to be executed at the certain frame number.
Each of the sensor channels is designed to be compatible with a sensor multiplexer, such as the 10359 used in the current Elphel multi-sensor cameras. These boards connect to three sensor boards and present themselves to the system as a single large sensor. Images are acquired simultaneously by all 3 imagers, one is immediately routed downstream and the two others are stored in the on-board memory. After the first image is transferred to the camera system board, data from the other two sensors is read from the memory and transferred in the same format as received from the sensors, so the system board receives data as if from the sensor with 3 times more lines. What is different in the NC393 camera code in comparison with NC353 is that now code is aware of the multiplexers and is able to apply different conversion to each sub-image and calculate histograms (used for autoexposure and white balance) for each sub-image. Current NC353 camera (and multisensor cameras based on the same design) have the same settings for the whole composite image coming from the multiplexer and have only one histogram window of interest.
Channel modules and parameterized and can be fine-tuned for particular applications to reduce resource usage. For example, the histogram modules can be either 18 (sufficient in most cases) or full 32 bit wide, histogram data may be buffered (required only for sensor with very small vertical blanking when using full frame histogram WOI) or not buffered. Depending on these settings either 1 or two block RAM hard macros are instantiated.
Histogram data generated from all 4 ports (from up to 16 sensors) is transferred to the system memory, and each of the 16 channels store data for the last 16 frames acquired. This multi-frame data storage eases timing requirements to the software that processes the histograms. This data is sent over the general purpose S_AXI_GP0 port. This medium-speed interface is quite adequate for this amount of data, high speed 64-bit wide AXI_HP* are reserved for the higher bandwidth image transfers.
NC393 Development progress: Multichannel memory controller for the multi-sensor camera
Development of the NC393 camera has just passed an important milestone – we completed HDL code that constitutes the core of this new camera, tested most of the Zynq-specific features that were not available in the older Spartan-3 FPGA used in our current NC353 devices. Next development phase will involve porting some of the existing code that deals with sensor interfacing, gamma correction, histograms, color conversion and JPEG/JP4 compression – code that was tested in the thousands of cameras and many billions of processed images, including the applications listed in Wikipedia. New camera is designed primarily for the multisensor applications – up to four connected directly to the system board and more through the multiplexers as we currently do in Eyesis4π cameras. It is the memory controller that had to be redesigned completely, the sensor and compressor channels can reuse most of the existing code and just have 4 instances of the same modules instead of a single one. Starting early this year I’ve got an opportunity to put aside other projects and work full time on the new camera code.
The new features tested include I/O elements needed to implement DDR3 interface (described in the earlier posts) and communication between the ARM cores (PS – processing system) and the FPGA (PL – programmable logic). Zynq has multiple channels of communication based on AXI standards, 2 of the interface types are used in the current design:
SAXI_GP0 – general purpose memory-mapped interface controlled by the processors, convenient to write data to various registers inside the FPGA fabric that determine the operation of the device. Read channel of the interface allows CPU to get status information back from the PL. This interface is 32-bit wide and it is not intended for high bandwidth applications.
AXI_HP0 – high speed channel allowing 64-bit wide transfers between the system memory and the FPGA logic. Zynq offers 4 of such channels, current design uses one to implement a two-directional “bridge” between the system memory and the dedicated DDR3 device connected to the FPGA and used as an image/video buffer. Two of the remaining channels will be used to transfer compressed images to the system memory (to stream out and/or record to HDD/SSD), and one for SATA interface.
Other AXI channels that are not yet used in NC393 code include ACP (Accelerator Coherency Port) that has the same bandwidth as the AXI_HP, but “sees” the memory the same way as the processors do (through the same cache levels), this port is intended as its name suggests for the “accelerators” – programmed logic tightly coupled with the CPU, where the latency is critical but the amount of data transferred is relatively small, so it will not disturb the normal cache usage by the processors.
Implementation of the HDL code that interacts with these AXI ports took more time than it should, partly because the Zynq manufacturer does not provide HDL code for simulation, only proprietary encrypted modules are available – modules that are useless for our preferred Free Software tools. When I tried to simulate AXI interfaces I only got the output from the following statement:
$display("Warning on instance %m : The Zynq-7000 All Programmable SoC does not have a simulation model. Behavioral simulation of Zynq-7000 (e.g. Zynq PS7 block) is not supported in any simulator. Please use the AXI BFM simulation model to verify the AXI transactions.");
We had to implement both the synthesizable HDL modules for our product and the simulation code for SAXI_GP and AXI_HP missing from the software distribution. This code definitely has limitations compared to the proprietary encrypted one – we implemented only the features needed in our design (for AXI_HP it does not provide 32-bit bus functionality). Nevertheless it seems to work for our application and is now available under GNU GPLv3 license for others to use as a part of x393 project at GiHub.
External memory controller is a rather intimate part of the system design and I do not believe it is possible to create an efficient one-size-fits-all code. Yes, Xilinx offers MIG IP that can be inserted into your custom design, but we need more control over what is going on inside it, the earlier post “DDR3 Memory Interface on Xilinx Zynq SOC – Free Software Compatible” describes the physical layer (PHY) of the implementation. Dynamic RAM devices impose multiple access restrictions, and the general purpose memory controller essentially tries to hide these details from the processes that use the memory, while keeping the data rate as close as possible to the theoretically available (clock frequency multiplied by bus width multiplied by two for DDR devices).
Some of the main specifics of the dynamic RAM devises are:
- Memory is page-oriented, access within the same page is fast, but opening/closing pages (“activate” and “precharge” terms are used in the device manuals) is slow
- Data transfer happens in multi-word “bursts”, DDR3 devices have normal bursts of 8 words (width depends on the memory organization) and short ones of 4 bursts, but short bursts use the same time as the 8-long ones so they do not offer advantage when transferring large amount of data. For our application we can consider memory device to be 128-bit (8*16 bits) wide
- Memory array is divided into “banks” (DDR3 has 8 of them), and transfers to/from one bank can take place with simultaneous activation/precharging of other one(s) as these operations do not use the data bus.
These features provide a clue – how to get a high average bandwidth. Basically there are 2 strategies:
- Consolidate multiple accesses to the same page. In the simplest form (common for the camera designs) write consecutive memory locations (like fill memory with the scan-line data from the sensor). With 16-bit wide memory it is possible to transfer up to 2048 bytes at the full memory bandwidth with just one “activate” in the beginning and one “precharge” (or auto-precharge) in the end.
- Design the memory addressing in such a way, that translation of the linear address to physical bank, page number (“row address” in DRAM terminology) and in-page address (“column address”) makes it likely to simultaneously operate multiple banks.
While the first clue is easy to follow, the second one is not. Depending on the particular clock speed/timing parameters, you may need 3-5 banks to interleave to provide full data bandwidth utilization, something rather difficult to achieve for random data access without making special assumptions about the nature of the application data.
Camera deals mostly with the 2-d data arrays and majority of scenarios use either sequential (scan-line ordered) access or depend on 2-d locality of the pixels (compression, de-warping, correlation, filtering, and more). This mode can use tiled access and read/write small rectangular pixel areas as atomic operations. Contrary to the general processing memory, latency is not usually critical for the image memory, access patterns are predictable and can be pre-optimized in advance, not at the run time during memory access.
This allows to optimize a custom memory controller dedicated to image acquisition, processing and compression, and in our case support multiple image sensors operating in parallel. Particular application may include optical image-guided UAVs and other robotic devices.
Mapping of the 2-d imaging objects to the DRAM memory addresses targets both sequential and tiled accesses. Each image scan line uses a single bank address (0..7) and increasing column addresses (2048 bytes or 128 bursts), then row addresses. Each group of 8 lines share the same row/column addresses and have individual banks for each row as shown on Fig.1.
{kind=link}
Figure 1. Memory layout for 2-d image objects
Atomic memory accesses are currently limited to ¼ of the 4KB BRAM memory blocks available in Xilinx Zynq FPGA part, that makes 64 bursts or ½ of the memory page. Crossing page boundary during sequential access requires precharge and activation of the different memory pages in the same bank, so while the code can split accesses automatically it is beneficial to align the full frame width to the multiple of the 64 bursts (1024 8-bit or 512 of 16-bit pixels).
Scanline frame accessMemory controller provides application modules with a scanline windowed access to the image frames defined by the memory start address and the full (possibly padded) frame width, measured in 16-byte bursts. Access window is defined by conventional X0, Y0, width (in bursts) and height (in lines/pixels).
{kind=link}
Figure 2 Access window in scanline mode
Scanline access module splits the requested window into a sequence of up to 64-burst data transfers, generates “page ready”, “frame ready” signals to application module, accepts “frame start”, “next page” signals. It also supports inter-channel synchronization by providing “next line number” output and “suspend” input. External module can compare last line number acquired from the sensor input channel and suspend compressor/image processing module, providing low-latency video.
Tiled frame accessMany image processing and compression algorithms consume or generate 2-d blocks(tiles) of data. Some applications require overlapping tiles, including regular JPEG compression of color images. While compression algorithm itself uses non-overlapping 8×8 pixel blocks (16×16 macroblocks for 4:2:0 mode), extra pixels around the blocks are needed for Bayer-to-YCbCr conversion that is convenient to implement right in front of the compressor where the data is already available in 2d format, not in scanline order as it comes out of the sensor.
{kind=link}
Figure 3 Access window in tiled mode
Tile overlap is needed both horizontally and vertically, but horizontal overlap is easy to implement in the application module just by using already buffered (in FPGA BlockRAM) data from the previous tile, while vertical overlap would need buffering the whole width of the sensor that would be not scalable for high resolution sensors and would require extra BlockRAM modules in the fabric. This is why the memory controller module provides only vertical tile overlap, accepting 3 byte-wide (width is limited by the total “area” of 64 bursts in a tile) parameters – tile width, tile height and tile step in addition to X0, Y0, window width and window height.
Tile internal structureMemory controller provides support for the 2 types of tiles. First type (Tile16) maps data to the sequence of bursts as vertical columns, each burst representing horizontal row of 16 (8-bpp mode) or 8 (16bpp mode) pixels.
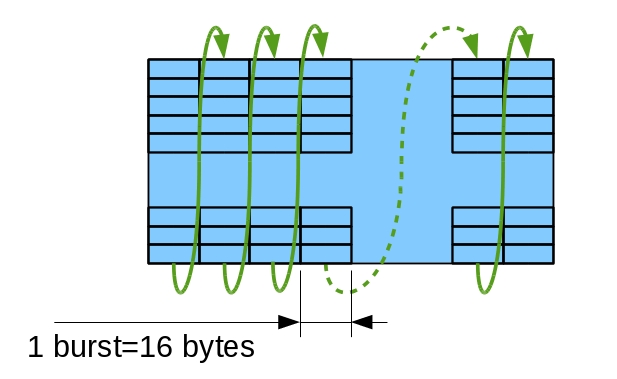{kind=link}
Figure 4a: Tile16 – tile with 1 burst-wide columns
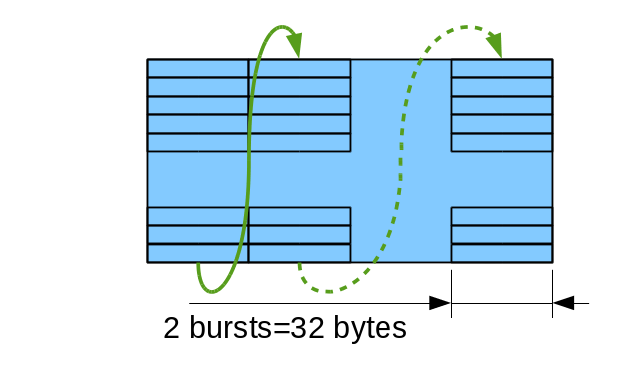{kind=link}
Figure 4b: Tile32 – tile with 2 burst-wide columns
Columns are traversed up to down, then left to write as shown on Fig. 4a. Due to memory timing restrictions this mode allows only some values for the tile height (0,6 and 7 modulo 8). Tile32 allows more variants for the tile height as there is more clock cycles between re-opening different page for the same bank, it can be (0,3,4,5,6,7 modulo 8). All tiles with the height of less than or equal to 8 are valid as it is possible to keep all banks open between columns of a tile, all heights are valid for the single-column tiles too. Single-column tile32 of maximal size (64 bursts) corresponds to a square area of 32×32 pixels in 8 bits per pixel mode.
NC393 HDL code and the memory controller implementationElphel camera code is built around the 16-channel DDR3 memory controller and at this stage the only modules that are not part of this controller are command and status distribution networks, system memory to external memory bridge over AXI_HP and temporary test modules to test controller functionality.
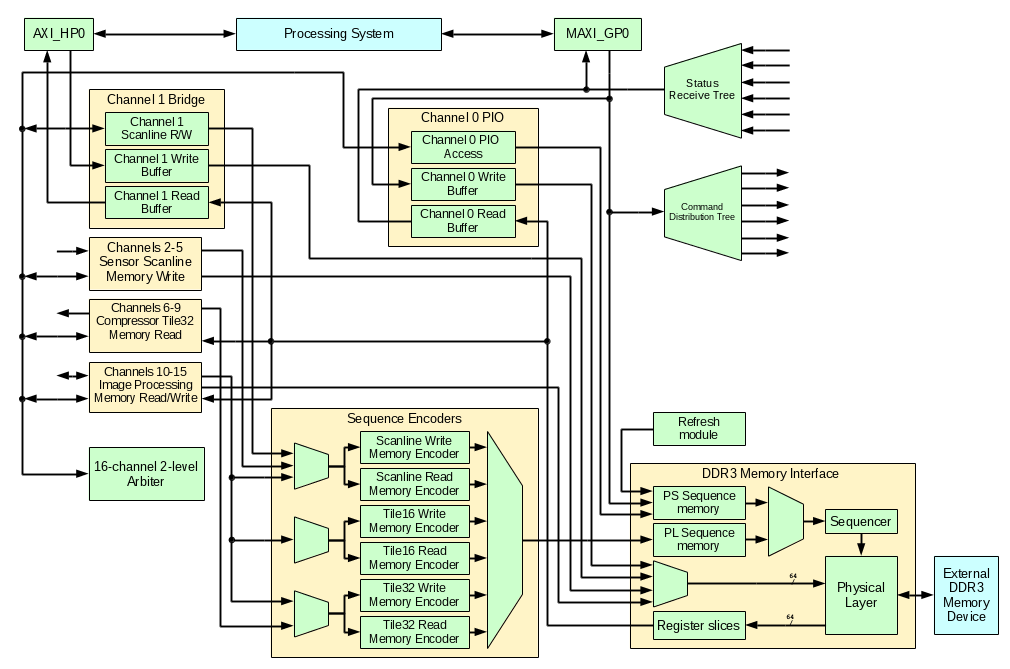{kind=link}
Figure 5. Memory controller block diagram
Command and status networksCommand distribution tree is designed to write data to various memory-mapped registers distributed over the whole design. All these registers are write-only (readback is optionally provided by a separate Block RAM-based module), so data paths can accommodate any number of register slices if needed to meet timing. This bus is a light-weight to minimize required routing resources of the FPGA, it requires only 9 data signals (9 address/data and a strobe) and can deliver 0 to 32 bits of data (configured by parameters at the destination module) sent over 1 to 6 clock cycles. Command distribution tree accepts commands from the software over the MAXI_GP0 or from a PL sequencer driven by the frame synchronization signals from the sensors – it will be ported from the current NC353 camera HDL code.
Status receive tree supplements the command tree and provides processing system with a feedback data from the distributed over the FPGA fabric modules. It includes a 256×32 register file available for PS read access with zero latency and a unidirectional tree of light-weight (10 signals) network that also includes multiplexers and status transmitters. Multiplexers route the messages (up to 6 clock cycles long depending on a payload) to the terminating register file. Status transmitters (controlled through the command distribution network) provide means to synchronize responses to the PS requests using 6-bit IDs, they send up to 26-bit status information either in response to a command or automatically when the input data changes.
Memory interface is forked from an earlier eddr3 project (there are some important bug fixes). In addition to the physical layer components it includes sequencer that generates address and control signals for memory device access following the program data prepared in advance. This sequence programs come from one of the two sources – PS Sequence Memory written under the software control and PL Sequence Memory filled in by one one of the Sequence encoders just before (during previous memory transaction) the execution. Both memories are made of 4KB Block RAM modules. PS sequences are used for memory refresh access instructions, memory initialization and calibration, any other pre-programmed memory operations that need to be executed following specific timing.
Memory interface is configurable with Verilog `define macros and can interface up to 16 concurrent channels, each being read-only, write-only or bidirectional. Each channel is supposed to have a 4KB block RAM buffer (or two of them for bidirectional channels) configured in SDP (simple dual port) mode with 64-bit wide input (for memory read) or 64-bit output (for memory write). Memory interface also provides channels with clock and control signals for the memory side of the buffers, other side of these dual-port buffers is under channel logic control, it may be clocked by a different source. Two layers of registers may be inserted in both input (16:1) multiplexer path and output distribution of the 64-bit wide data buses that may need routing to different parts of the device.
Channel buffers are based on 4KB block RAM modules, each split into 4 of 1KB pages, making them suitable for up to 64 of 16-byte bursts transfers. Of the four pages one (in some overlapping tiles applications – two) is in use by the channel logic (being consumed or generated), another is used by the transfer to/from the DRAM memory, and the remaining ones provide needed buffering when memory is in use by the other channels.
16-channel arbiter accepts two levels of urgency (“want” and “need” signals) from the channel controllers. In most cases memory read channels generate “need” if there is at least one empty buffer page and the channel will need it later (not the last pages in a frame), “need” is generated when the channel is consuming the last available page. Similarly for the memory write channels – “want” is generated when there is at least one completed page, “need” – when there is no empty pages left. Channels that can wait for the data can skip raising the “need” signal leaving more resources to other channels that are tied to constant data rate data (such as inputs from the sensors).
In addition to the two levels of urgency (channels with ”need” requests are served before “want” ones compete) arbiter provides channel priorities. Each channel has associated counter that increments at each event (new request or request grant), taking care of the simultaneous requests by static priority by channel number. The channel having highest counter value wins, receives “grant” signal and that channel counter is reset to the specified channel priority value, so priority 0 makes that channel to wait maximal time.
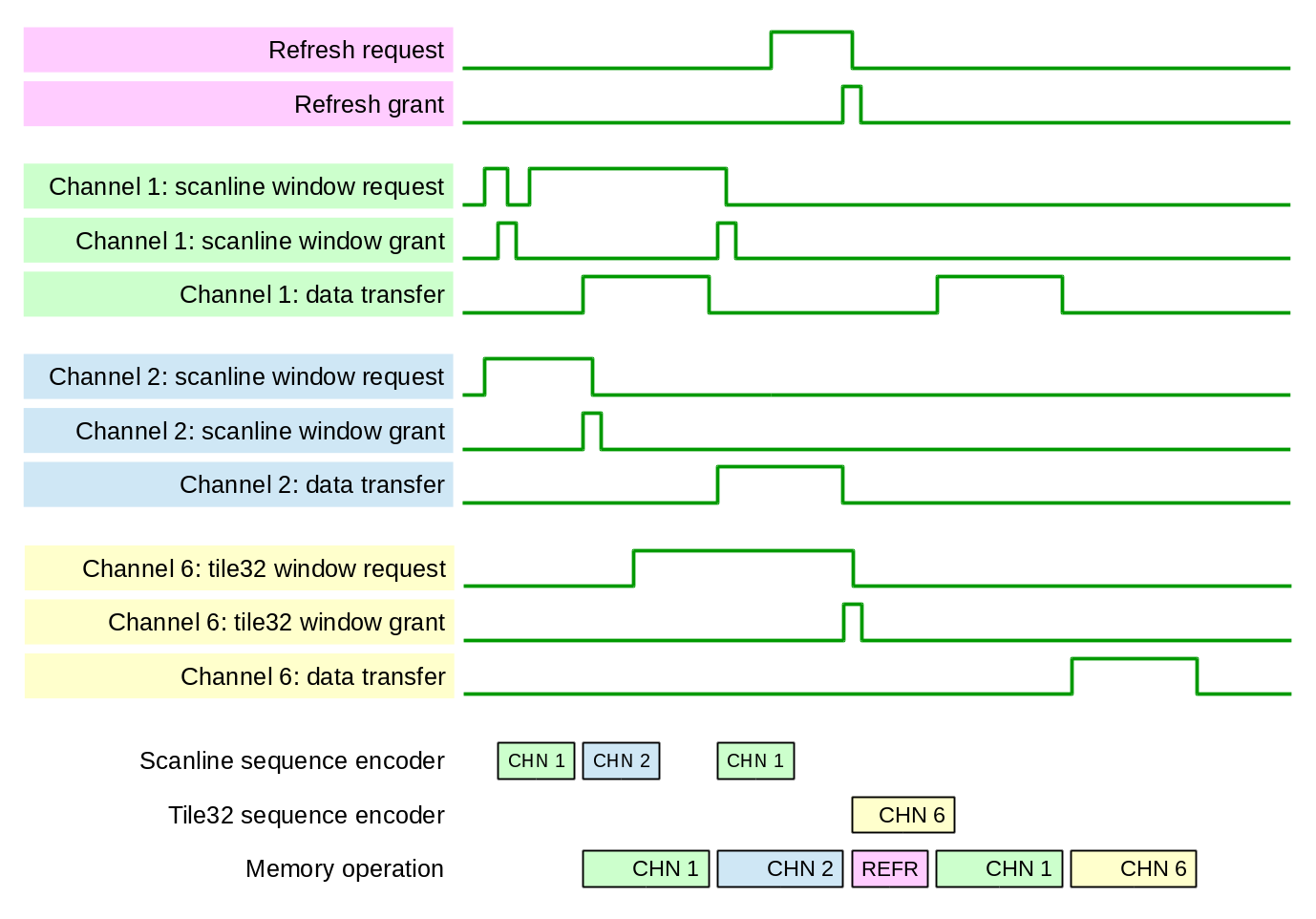{kind=link}
Figure 6. Memory access arbitration and timing
Sequence generation takes less time than the actual memory access, and channel arbitration happens when the previous sequence data is sent for execution. Fig. 6 shows that channel 2 sequence is started to be transferred to the PL Sequence Memory as soon as the memory interface starts to execute sequence for channel 1.
There is an additional arbitration just before starting to execute a sequence – if refresh module (it does not need to transfer sequence data as it is already in the PS Sequence Memory) generates “want” or “need” request, it competes against the already granted channel that has the sequence ready to be executed – Fig. 6 shows how REFR sequence passes the CHN1 that is ready to be executed. The sequence FIFO in PL Sequence Memory allows only one sequence to be buffered. This limit is imposed to reduce waiting for service of the urgent (“need”) requests while not using a more complicated mechanism that would allow such requests to pass other channel non-urgent (“want”) requests in the sequence memory FIFO. It is still a possibility for the future improvements to allow efficient execution of significantly different size memory transfers.
Sequence encoders are shared between the channels – the channel that wins the arbitration is granted to generate a memory access sequence. Currently there are 6 of such modules that generated scanline read, tile16 and tile32 (see Fig. 4a-b) and similar for memory writes. These modules accept address and size parameters from the window access controllers and use HDL-encoded templates to generate control sequence for the next memory access operation.
Channel window access controllersWindow access controllers implement access to selected rectangular areas inside the image frame. There are two types currently available – scanline access (Fig. 2) and tiled access (Fig.3). Distinction between read and write modes, and between tile16 and tile32 modes are passed as run-time parameters. They are used later to select the specific sequence encoder each time the request is granted by the arbiter. These modules require individual instances for each channel that uses them as they have to keep track of the related channel buffer, tile location and other module state variables.
Additional controllers will be developed for other types of accesses when needed by the image processing algorithms that may need other types of memory accesses. Example application may be a distortion correction procedure where either input or output use tiles that are not defined by a regular grid).
Channel 0 is designed for programmable access to the memory. It uses PS Sequence Memory written through MAXI_GP0 under the software control. It has both read and write buffers for operations that involve data transfer, it is used for memory initialization and calibration/training, it can also be used to test other access sequences without re-generation of the bitstream.
Channel 1 implements a fast bi-directional bridge between the system memory and the dedicated image memory. On the system side it uses AXI_HP0 port in 64-bit mode, on the image memory side it implements a scanline window access It is possible to either fill the selected window in the image memory with the consecutive data from the system memory, or read image memory window to a linear array in the system memory.
Channels 2-5 will be used to record data from the four sensor ports, currently one channel is connected to 2 buffers connected to the SAXI_GP0 interface for testing scanline windowed memory access.
Channels 6-9 will be used in tile32 mode to read 2d data for image compression. Temporary implementation uses 2 channels connected to SAXI_GP0 read/write for testing purposes.
Remaining six channels may be used for application-specific image processing.
The list of the tools used for this project is the same as listed for the earlier eddr3 project. The only difference is that now it is Eclipse Luna instead of Kepler, and some bugs in VDT plugin are fixed – bugs that revealed themselves while this plugin was being used with gradually growing code base.
The x393 project code itself is available under GNU GPLv3 Free Software license, does not depend on any undocumented or encrypted “IP” modules and can be simulated with the Free Software tools. Project configuration files allow importing it to Eclipse IDE when VDT plugin is installed.
FPGA to DDR3 memory interface: step-by-step timing calibration and set up
Working with the DDR3 Memory interface I was not able to avoid the temptation to investigate more the very useful feature of the modern FPGA devices – individually programmed input/output delay elements on all (or at least many) of its pins. This is needed to both prepare to increase the memory clock frequency and to be able to individually adjust the timing on other pads, such as the sensor ports, especially when switching from the parallel to high speed serial interface of the modern image sensors.
Xilinx Zynq device we are using has both input and output delays on all low-voltage pins used for the memory interface in the camera, but only input ones on the higher voltage range I/O banks. Luckily enough image sensors connected to these banks need just that – data rate to the sensors is much lower than the rate of the data they generate and send to the FPGA.
Adjustment of the optimal pin delays for the memory interface can be done in several ways, and many applications require that it should be either all implemented in hardware or use very limited CPU resources – that is the case when the memory to be set up is the main system memory and so CPU can not use it. On the other hand when the memory is connected to the FPGA part of the system that is already running with full software capabilities it is possible to use more elaborate algorithms.
I call it for myself “the Apple ][ principle” - do not use extra hardware for what can be done in software. In the case of the delay calibration for the memory interface it should be possible to use a reasonable model of the delay elements, perform measurements and calculate the parameters of such model, and finally calculate the optimal settings for each programmable component. Performing full measurements and performing parameter fitting can be a computationally intensive procedure (current Python implementation runs 10 minutes) but calculating the optimal settings from the parameters is very simple and fast. It is also reasonable to expect that individual parameters have simple dependence on the temperature so it will be easy to adjust parameters to the varying system temperature. Another benefit of such approach that it can use delay elements with even non-monotonic performance (that is sometimes in case when using FINEDELAY elements) and finally – the internal parameters of the delay elements do not depend on the clock frequency, so parameters can be measured at lower clock frequency and then settings can be re-calculated for the higher one. Adjusting timing parameters at the target frequency can be more difficult as there can be much smaller windows of the combination of the parameters that allow memory device to operate, it may be not possible to probe marginal values of some delays (to calculate the optimal center value) as it may violate other timing parameters.
The procedure described below can be used to measure the delay parameters of the memory interface and find the optimal combinations of the settings requiring no manual adjustments of the initial values. The software is written in Python and is a part of the Elphel GitHub repository x393 as x393/py393 PyDev project.
The Python code includes a module that can parse Verilog header files with parameter definitions so all the changes in the HDL code are automatically applied to the Python program, running the program on the target hardware generates updated values of the delay settings as a Verilog file, so these measured values can be used in simulation. This program is of course designed to run on the target platform, but most of the processing can be tested on a host computer - the project repository contains a set of measured data as a Python pickle file that can be loaded in the program with a command "load_mcntrl dbg/x393_mcntrl.pickle". Program can run automatically using the command file provided through the arguments, it also supports interactive mode. Most of the functions defined in the program modules are exposed to the program CLI, so it is possible to launch them, get basic usage help. Same is true for the Verilog parameters and macro defines - they are available for searching and it is possible to view their values.
Delay elements in the memory interface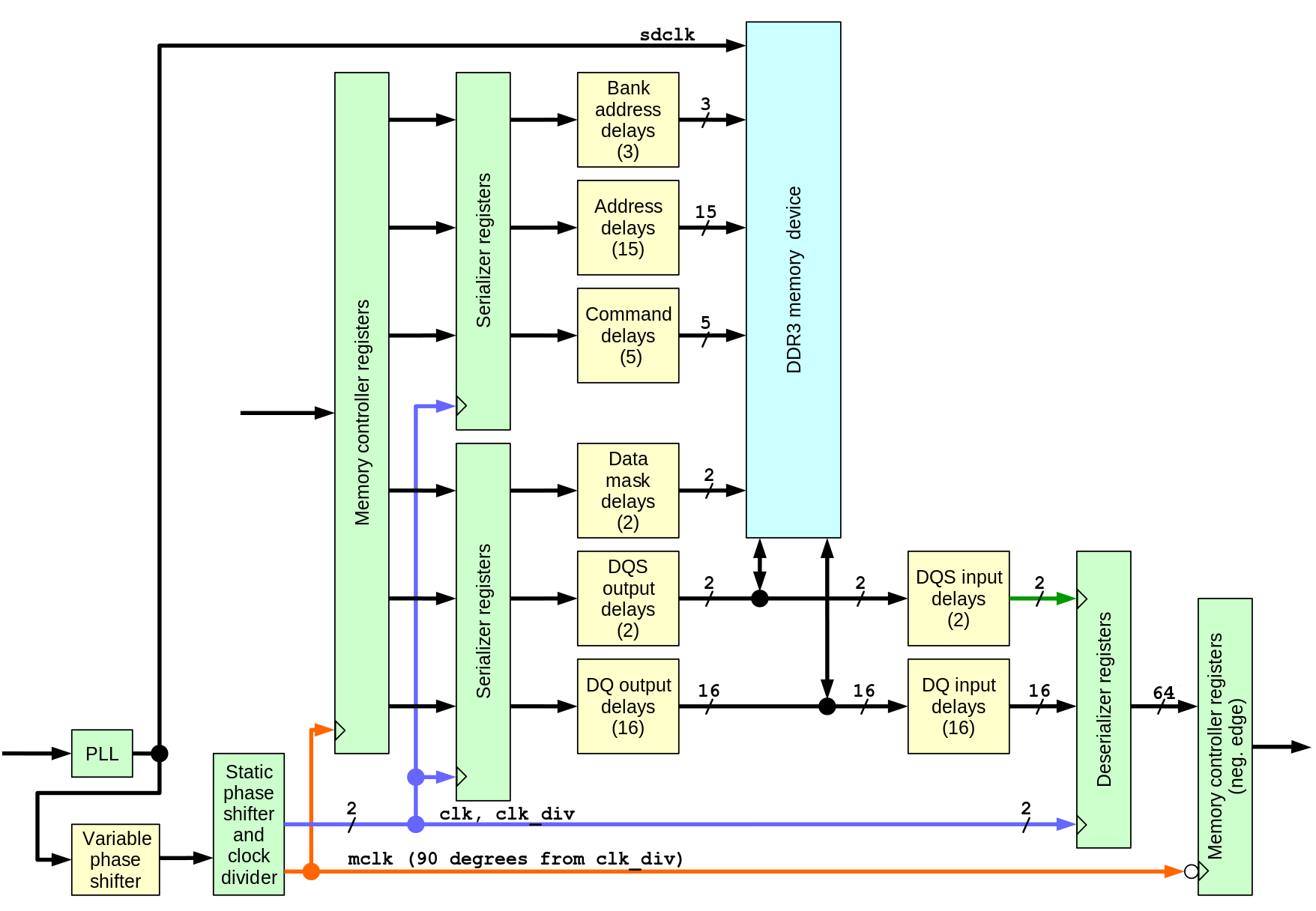{kind=link}
Fig.1 Memory interface diagram showing signal paths and delays
There are total 61 programmable delays and a programmable phase shifter as a part of the clock management circuitry. Of these delays 57 are currently controlled – data mask signals are not used in this application (when needed they can be adjusted by the similar procedure as DQ output delays), ODT signal has more relaxed timing and the CKE (clock enable) is not combined with the other signals. There are 3 clock signals generated by the same clock management module with statically programmed delays: clk (same frequency as the memory clock), clk_div (half memory frequency) and mclk – also half frequency, but with 90 degree phase shift with respect to clk_div, it is driving the memory controller logic. Full list of the clock signals and their description is provided in the project.
Variable phase shifter (with the current 400 Mhz memory clock it has 112 steps per full clock period) is essentially providing variable phase clock driving the memory device, but to avoid dependence on the memory internal PLL circuitry, memory is driven by the non-adjusted clock, and programmed phase shift is applied to all other clock signals instead.
Address/control signals and data to be written to the memory device originate in the registers and Block RAM of the controller running at mclk global clock, then they go through serializers (OSERDESE2 for synthesis, OSERDESE1 for simulation to avoid undisclosed code modules). Serializers use two clocks and in this design the slower clk_div is ¾ of the mclk period later than mclk itself to guarantee positive setup time when crossing the clock boundary. Serializers for data, data mask and DQS strobes operate in DDR mode, while the ones for address and command signals use single data rate mode. Each of this signals pass through individual 32-tap delay with nominal 78 ps/step, followed by a a 5-tap fine delay element (ODELAYE2_FINEDELAY) and then go to the external memory device.
On the way back the data read from the memory and the read strobes (one per each data byte) pass through IDELAYE2_FINEDELAY elements and then strobes pass through BUFIO clock buffers that drive input clock ports of the deserializers ( ISERDESE2 for synthesis, ISERDESE1 for simulation), while the same (as used for the output serializers) clk and clk_div drive the system-synchronous ports. When crossing clock boundary to the mclk registers that receive data from the deserializers use the falling edge of mclk and there is again ¾ of mclk period to guarantee positive setup time.
The delay measurement procedure involves varying the delay that has uniform phase shift step (1/112 memory clock period) and adjustment of the variable “analog” pin delays that have some uncertainty: constant shift, scale (delay per step) and non-linearity. The measurement steps that require writing data to the memory and reading it back, and so depending on the periodic memory refresh, the automatic refresh is temporarily turned off when the clock phase and command delays are modified.
Measuring delays in the signal paths and setting memory interface timing Step 1 : Finding valid command/address delays for each clock phase settingThe first thing to do to be able to operate the memory is to find the address/command line delay that is safe to use with each clock phase and/or find what values of the phase shift are valid. The address and command signals use single data rate (sampled at the leading edge of the clock by the memory device) so it is easier to satisfy the setup/hold requirements than for the data. DDR3 devices provide a special “write levelling” mode of operation that requires only clock, address/command lines and DQS output strobes providing result on the data bus. At this stage timing of the read data is not critical as the data data stay the same for the same DQS timing, and it is either 0×00 or 0×01 in each of the data bytes.
It is possible to try reading data in this mode (reading multiple data words and discarding groups of first and last one no remove dependence of read data timing) and if the result is neither 0×00 nor 0×01 then reset the memory, change the command delay (or phase) by say ¼ of the clock period, and start over again. If the result matches the write levelling pattern it is possible to find the marginal value value of the address delay by varying delay of address bit 7 when writing the Mode Register 1 (MR1) – this bit sets the write levelling mode, if it was 0 then the data bus will remain in high impedance state.
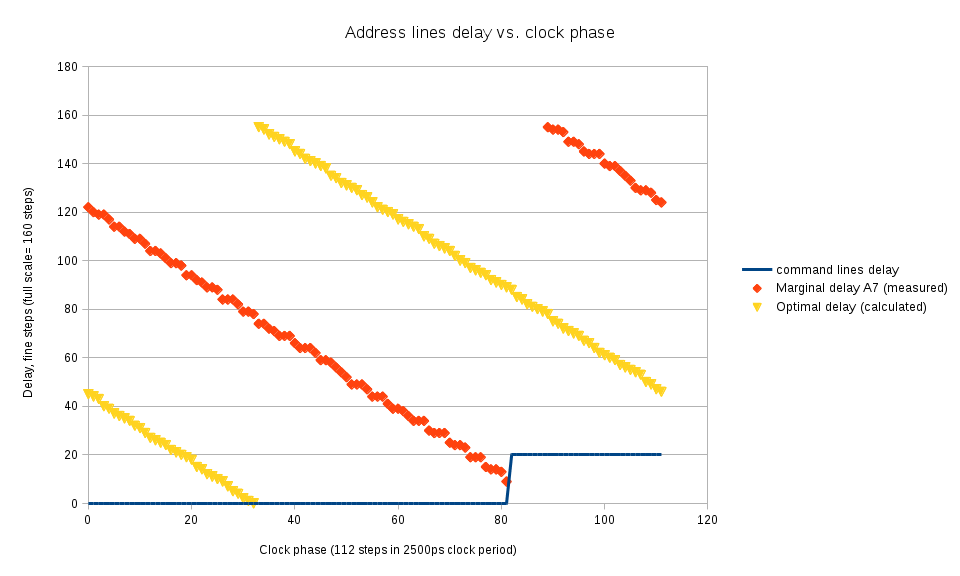{kind=link}
Fig.2 Finding the command/address lines delay for each clock phase
Memory controller drives address lines in “lazy” mode leaving them unchanged when they are not needed (during inactive NOP commands) so it is easier to check if A[7] low → high transition happens too late. Additionally the tested write levelling command have to be preceded by some other command with A[7] at low level.
Figure 2 shows the process of scanning over phases and finding the longest delay on A[7] line that still turns on the write levelling mode (shown with red diamonds). Command line delays are kept at zero until at phase 82 the delay on A[7] line becomes smaller than a preset limit (command lines are almost too late themselves), at this phase the command line delay is increased so the command is recognized in the next clock cycle and so the marginal value of A[7] is also increased by the full clock period. With the current settings the full delay range is almost exactly equal to the clock period, this will not be the case at higher memory clock rates (delays will cover more than a period) or increasing the delay calibration clock rate from 200 MHz to 300 MHz (delays will cover les than a period). On the Figure 2 there is a small gap (to phase=86) when the marginal delay for A[7] can not be measured as it would exceed the maximal delay value available in OSERDESE2 element.
Yellow triangles show the optimal values for the A[7] delay calculated by applying linear interpolation to the marginal values and shifting the result horizontally by ½ of the clock period (56 phase steps).
At this preliminary stage optimal command/address delays are assumed to be the same as for the A[7] – they are connected to the same I/O bank. Later it will be possible to optimize each signal delay individually, when switching to the higher frequency the relative differences between lines can be assumed the be the same and can be applied accordingly.
During the next stages of the delay measurement the command and address lines delay values are all set whenever the clock phase is changed.
Step 2: Measuring individual delays for command (RAS,CAS,WE) lines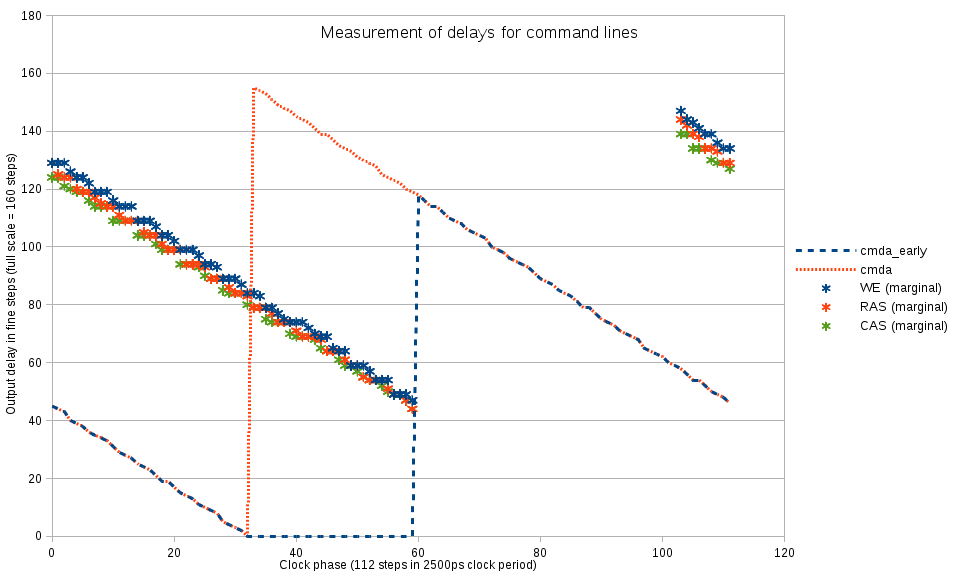{kind=link}
Fig.3 Command lines delays measurement
When the approximate value for the optimal delay for the address/command lines is known it is possible to individually calibrate delay for the command lines. The mode register set command involves high (inactive) to low (active) state on all 3 of them, so it is possible to probe turning on the write levelling mode when 2 of the the 3 command lines (and all the bank and address lines) are set with the optimal values, while the delay on the remaining command line is varied. Sometimes this procedure leads to the memory entering undefined/non-operational state (write levelling pattern is not detected even after restoring known-good delay values), when such condition is detected, the program resets and re-initializes the memory device.
To increase the range of the usable phases the other command/address lines are kept at delay=0 while there still is a safe margin of the setup time with respect to memory clock (from phase = 32 to 60 on Fig. 3)
Step 3: Write levelling – finding the optimal DQS output delays for clock phase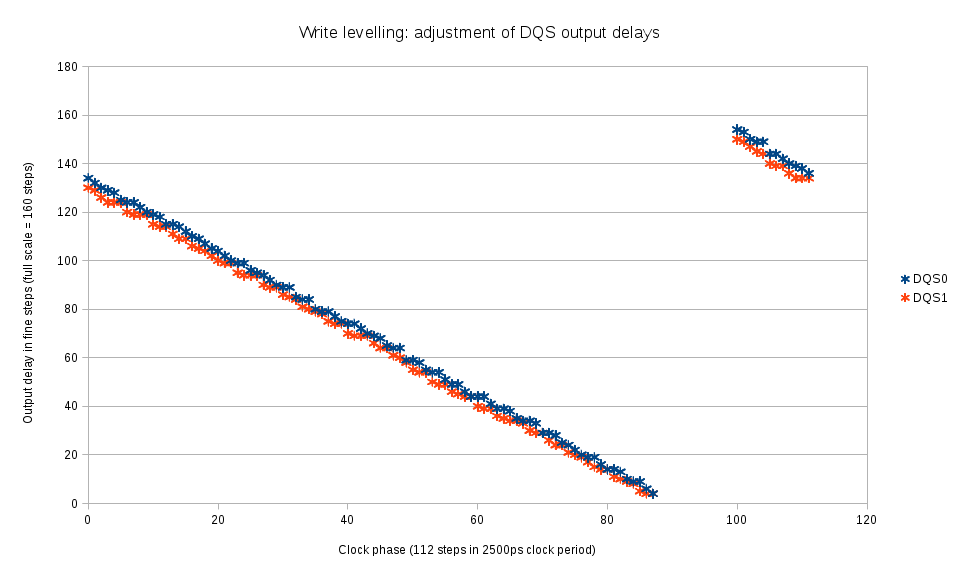{kind=link}
Fig.4 DQS output delay measurement with write levelling mode
This special mode of DDR3 devices operation is intended to adjust the DQS signal generated by the controller to the clock as seen by the memory device, it measures clock value at the leading edge of the DQS signals and replies with either 0×00 (clock was low) or 0×01 (clock was high) on each data byte of DQ signals.
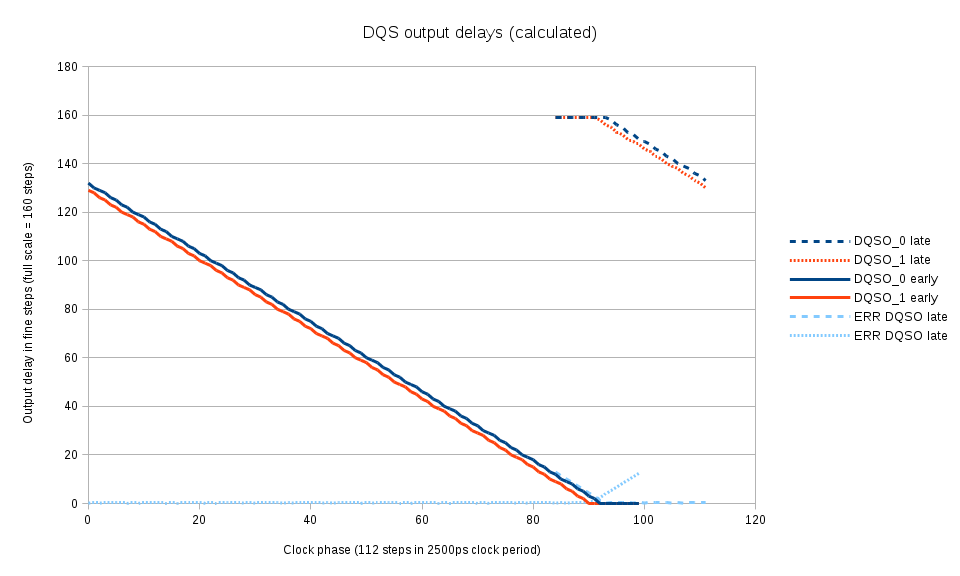{kind=link}
Fig.5 Calculated optimal DQS output delays for each clock phase
The clock phase is scanned over the full period and for each phase the marginal (switching from 0×00 to 0×01) DQS output delay is measured for each of the byte lanes. This procedure directly results in the optimal values of the DQS output delay values, there is no need to shift them by a half-period. Fig. 5 shows the calculated by linear interpolation values of the DQS output delays for each phase. To increase the range of DQ vs. DQS delay measurements, the DQS output signals are allowed to slightly deviate from the optimal – Fig. 5 shows “early” and “late” branches and the amount of deviation.
The similar calculation is performed later once more time when additional data from co-measurement of DQ output delays and DQS output delays becomes available. At that stage it is possible to account for non-uniform fine delay steps of DQS output lines.
Step 4: Fixed pattern measurementsDDR3 memory devices have another special operational mode intended for timing set up that does not depend on actual data being written to the memory or read back. This is reading a predefined pattern from the device, currently only one pattern is defined – it is just alternating 0-1-0-1… on each of the data lines simultaneously. In this step the 11 of the 8-word bursts are read from the memory, then only the middle 8 bursts are processed, so there is no dependence on the (yet) wrong timing settings that result in the wrong synchronization of the data bursts. That provides 64 data words, half being in even (starting from 0) positions that are supposed to be zeros, and half in odd ones (should read all 1-s), and then total number of ones is calculated for each data bit for odd and even slots – 16 pairs of numbers in the range of zero to 32. These results depend on the difference between delays in the data and data strobe signal paths and allow detection of 4 different events in each data line: alignment of the leading edge on the DQ line to the leading edge of the DQS signal (as seen at the de-serializer inputs), trailing edge of the DQ to leading one of DQS and the same leading and trailing DQ to the trailing DQS. They are measured as transitions from 0 to 1 and from 1 to zero separately for even and odd data samples.
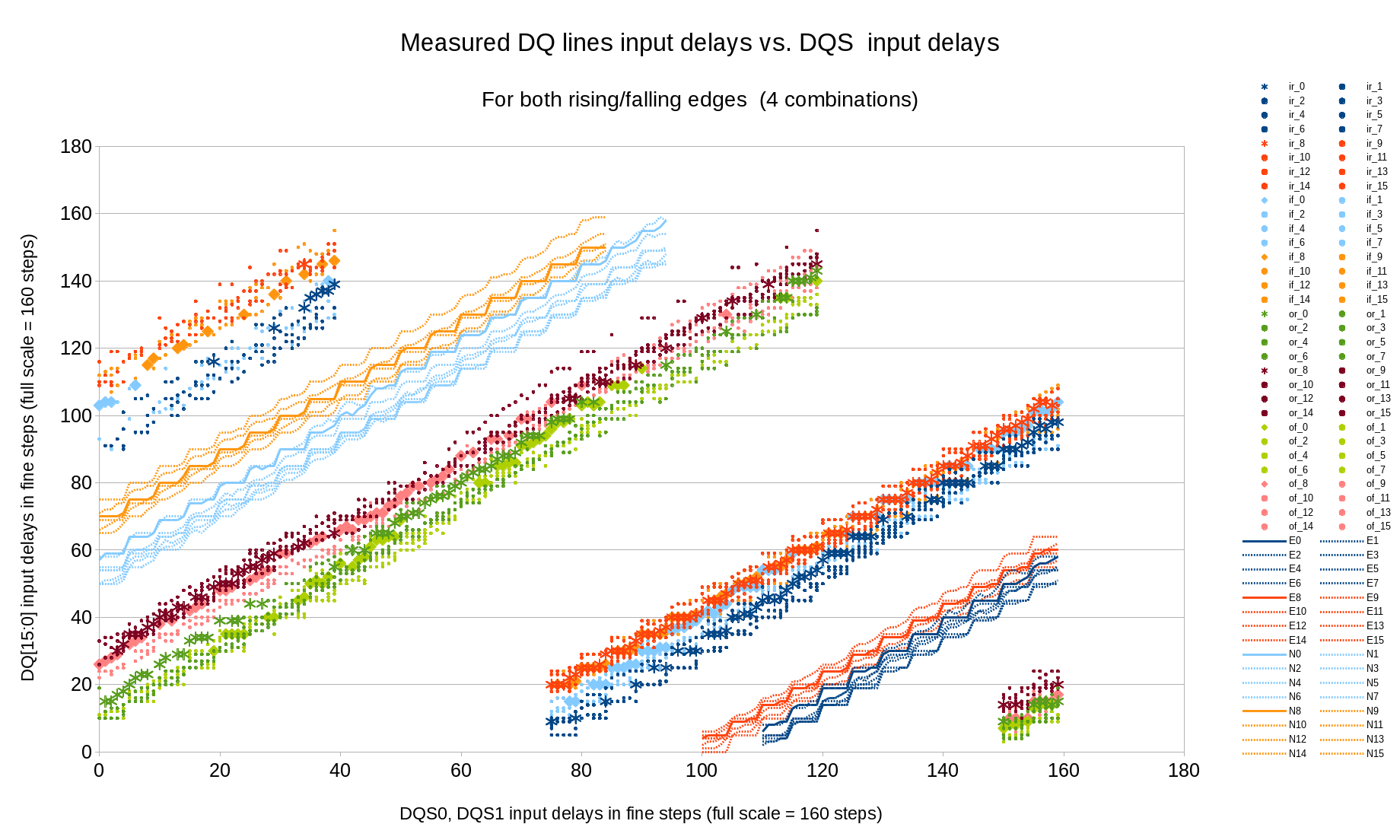{kind=link}
Fig.6 Measured (marginal) and calculated (optimal) DQ input delays vs. DQS input delays
Most results have 0 or 32 values (all data words are read 0 or 1), but some provide intermediate “analog” results when corresponding words are read differently, depending on some uncontrolled factors. Later processing assumes that the difference from the middle value (16) is proportional to the difference between the measured (by the settings) delay value and the actual one. Additionally if the number of such analog samples is sufficient, it is possible to process only them and discard “binary” (all 0-s/all 1-s transitions).
This measurement can be made with any clock phase setting. Even as normally there is a certain relation between the phase and DQS delay (measured in the next step), wrong setting shifts read data by the full clock period or 2 bits for each DQ line, with 0-1-0-1 pattern there is no difference caused by such shift and we are discarding first and last data bursts where such shift could be noticed.
Figure 6 shows measured 4 variants for each data bit, ‘ir_*” for in-phase (DQ to DQS), DQ rising, “if” in-phase DQ falling, ‘or’ – opposite phase rising and ‘of’ – opposite phase falling. Only “analog” samples are kept. “E*” and “N*” show the calculated optimal DQ* delay for each DQS delay value. Calculation is performed with Levenberg-Marquardt algorithm with the delay model describe late in this article, the same program method is used both for input and output delays. The visible waves on the result curves are caused by the non-uniformity of the combined 32-tap main delays with the additional 5-tap fine delay elements, different amplitude of these waves is caused by the phase shift between the DQ and DQS lines (“phase” here is the fine delay (0..5) value – the full 0..159 delay modulo 5).
Step 5: Measuring DQS input delay vs. clock phaseDeserializers use both memory-synchronous clock (derived from DQS) and system-synchronous clk and clk_div, so there is a certain optimal phase shift between the two, allowing maximal deviation of the memory-synchronous input clock.
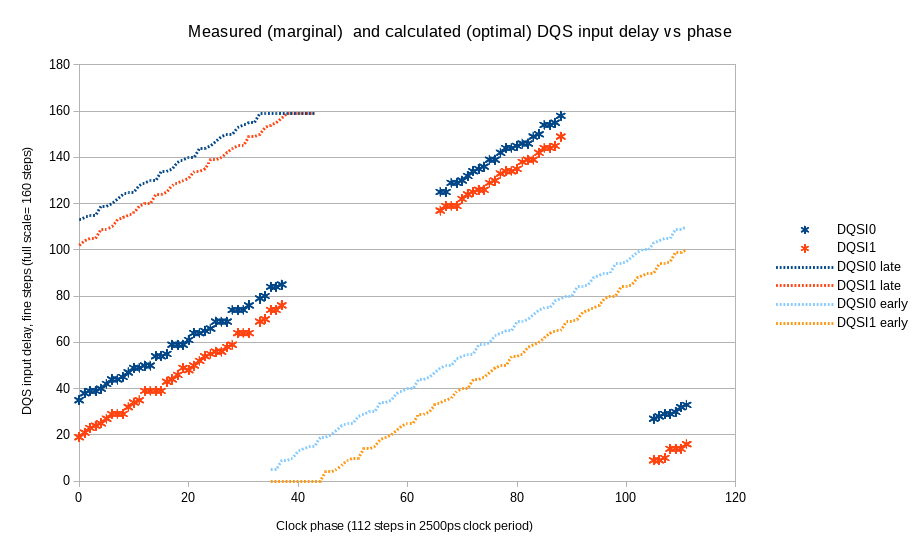{kind=link}
Fig.7 Measured (marginal) and calculated (optimal) DQS input delays vs. clock phase
Data is crossing clock domains boundary at a single clock rate (2 bits at a time for each data line), so using fixed pattern of alternating 0-1-0-1… can not be used – regardless of the phase shift it will be the same “01” pair. For this reason we use actual read data command, not a special read pattern mode. Random data that is present in the memory array after power up can be used, but the program is writing a 0-0-1-1-0-0- 11… pattern for each data bit. This pattern will provide different di-bit value in each DQ line, even if the write DQ to DQS timing is not yet determined, so the actual data can be any of X-0-X-1-X- 0… where X can quasi-randomly be any of 0 or 1. The pattern is recorded once, then the data is read with different DQS input delays (DQ input delays are set according to step 4 results), comparing only the middle portion with the beginning/end discarded as before. The marginal DQS delay is detected as the value when the read data changes from the original value.
Figure 7 shows results of such measurements as well as the calculated optimal input delays for DQS lines. This calculation uses both Step 5 (DQS vs. phase) and Step 4 (DQ vs. DQS) measuremts and accounts for the fine delay non-uniformity.
Step 6: DQ to DQS output delays measurements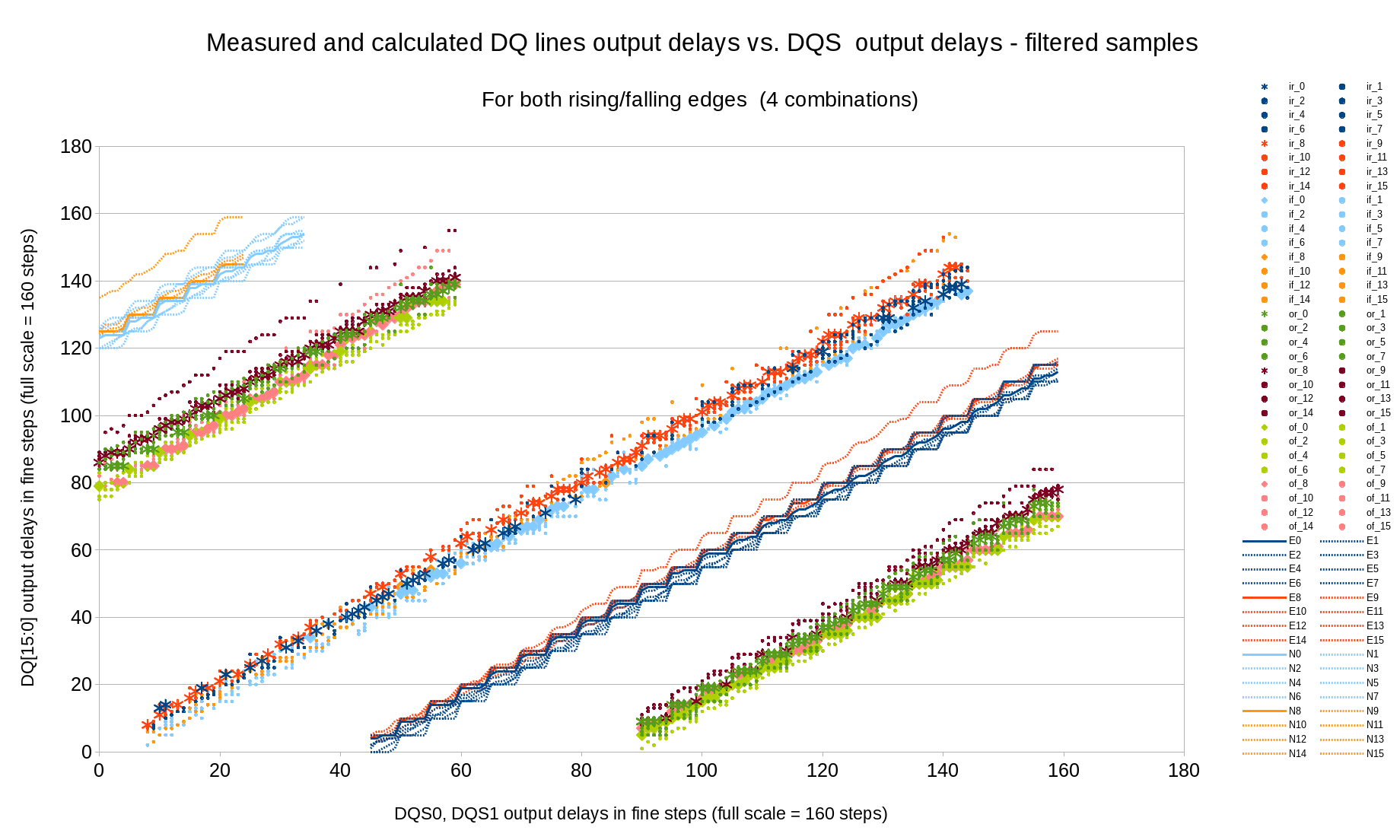{kind=link}
Fig.8 Measured (marginal) and calculated (optimal) DQ input delays vs. DQS output delays
This measurement is performed similarly to step 4 when DQ to DQS input delays relation was probed with a fixed pattern readout mode. Now we already have known settings for the memory read operation and can rely on it to adjust write mode (output) delays. Alternating 0-1-0-1 sequence in every line similar to the pattern mode is recorded with various DQS output delay values, for each DQS delay appropriate phase and address/command delay values are used. Input delays (for DQS and DQ) are set for each phase using data from the previous steps and the data written with different DQ output delay is read back, then processed in the same way as in Step 4.
Figure 8 presents the relation between DQ and DQS output delays, and the result of combining Step 6 measurements with Step 3 (write levelling) – optimal DQ and DQS output delay values for different clock phase can be seen on Figure 9 that shows all the delays. Allowing some deviation from the DQS to clock alignment (this requirement is more relaxed than DQ-to-DQS delays) results into 2 alternative solutions for the same phase shift near phase=95, use of the higher memory clock rates will result in more of such multi-solution areas even without deviation from the optimal values.
Step 7: Measuring individual output delays for all address and bank linesHaving almost calibrated read and write memory operations it is now possible to set up output delays for each of the remaining address and bank lines (so far only A[7] was measured, other lines were just assumed to be the same). This measurement is done with writing some “good” pattern to a specific bank/row/column page (column address uses the low bits of the row address), and a “bad” data to all pages different by 1 of the address or bank bits. For this test the refresh sequence (it is loaded by the software, it is not hard-wired in the HDL code) was modified to provide specified data on the bank/address lines that is “don’t care” for this operation. These values are set to be inverted values to the “good” address, and the refresh command was manually requested before the read operation, making sure that the command will cause all the address/bank bits to be inverted.
All the phase values are scanned, for each phase the command and address delays are set to the optimal values as defined so far, and only one line at a time delay was modified to find the marginal value that causes the readout of the wrong data block.
This measurement is performed twice – fist with “good” address of all zeros, then – with all ones and results averaged for low → high and high → low address line transitions.
Step 8: Selecting valid parameter combinations for readout and write modes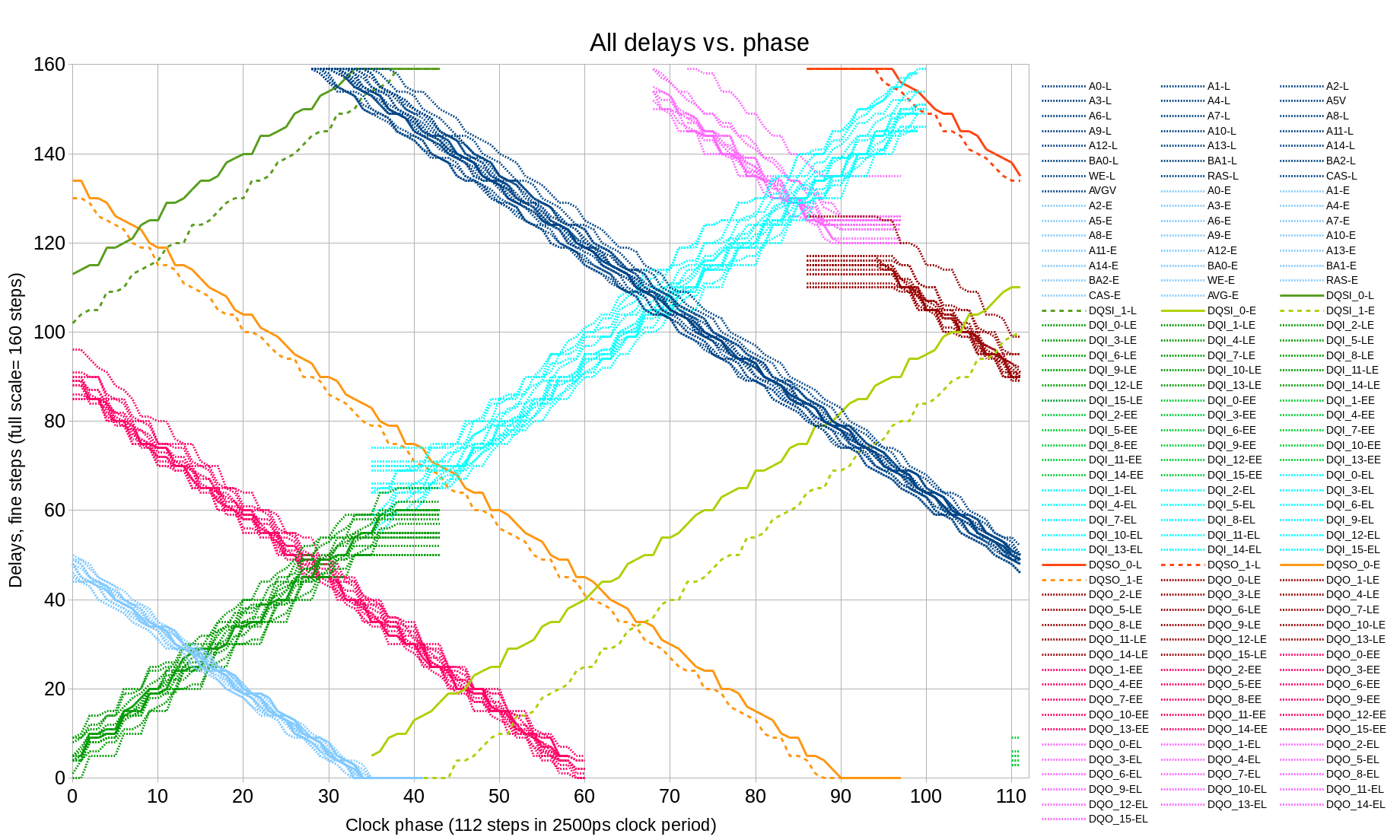{kind=link}
Fig.9 All delays vs. clock phase
Figure 9 combines all the data acquired so far as a function of the clock phase shift. Most of the delays do not change when the new bitstream is generated after the modification of the HDL code – the involved delays are defined by the fixed I/O circuitry and PCB/package routing. Only two of the signals involve FPGA fabric routes – DQS input signals that include BUFIO clock buffers, these buffers can be selected differently and routed differently by the tools. These signals also show the largest difference one the graph (two pairs of the green lines – solid and dashed).
There are additional requirements that are not shown on the Figure 9. DQ signals from the memory should arrive to the deserializer ¼ clock period earlier than the leading edge of the first DQS pulse, not 1 ¼ or not ¾ later – the measurements so far where made to the nearest clock period. Memory device generates exactly the required number of DQS transitions, so if the data arrives 1 clock too early, then the first two words will be lost, if it arrives 1 clock too late – the last two words will be lost.
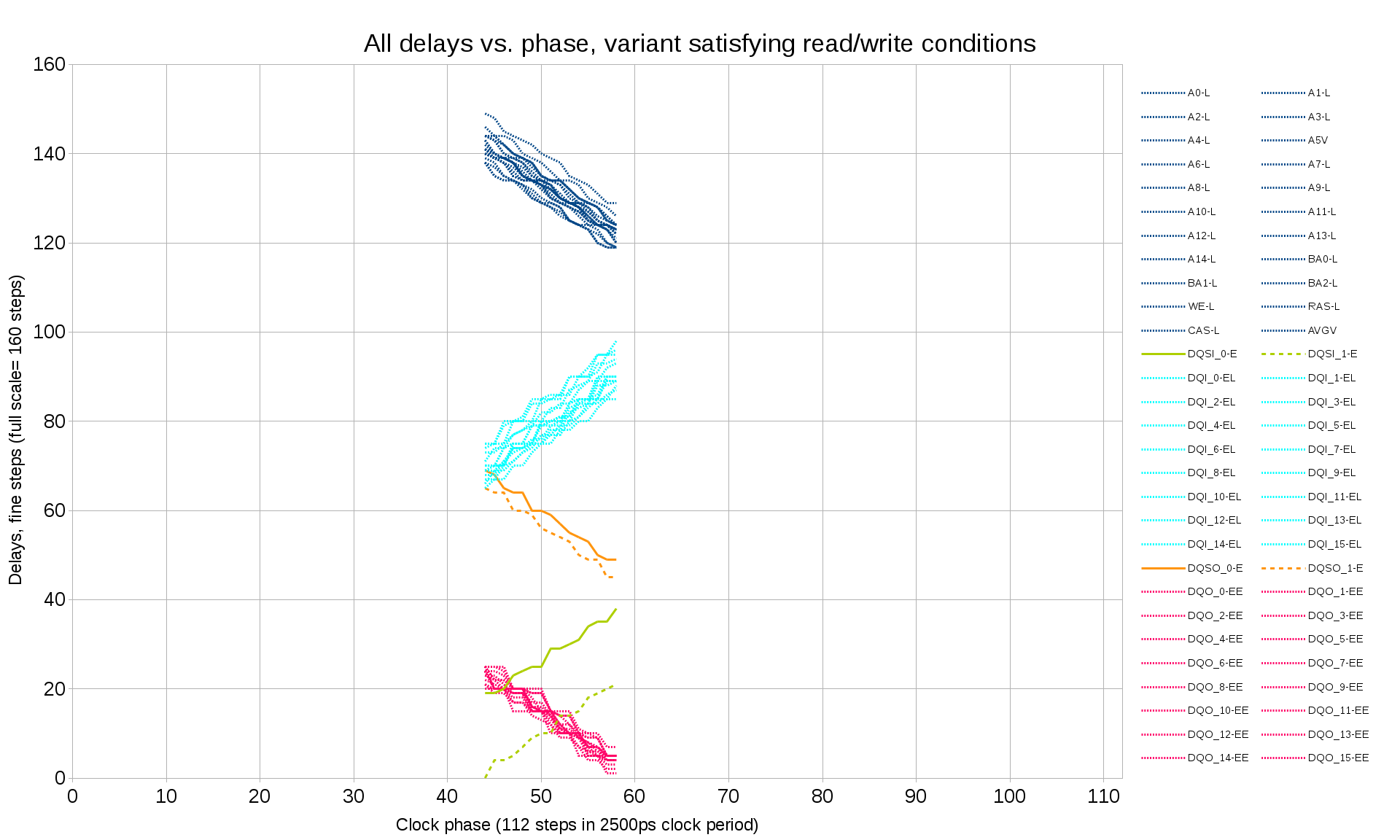{kind=link}
Fig.10 All delays vs. clock phase, filtered to satisfy period-correct write/read conditions
For this final step the alternative variants of the setting that differ by the full clock periods are selected and tested. First the block with incremented (each word is the previous one plus 1) data is recorded and then the smaller block completely inside the recorded one and not using the first/last bursts is read back. The write mode is not yet set up, so the first/last recorded burst can not be trusted, but the middle ones should be recorded incrementally, so any differences from this pattern have to be caused by the incorrect readout settings.
After removing invalid parameter combinations defining the readout mode we can trust that the full block readout has all the words valid. Then we can do the same for the write mode and check which of the variants (if any) provide correct memory write operation. In the test case (one particular hardware sample and one clock frequency there was exactly one variant (as shown on the Figure 10) and the final settings can use the center of the range. With higher clock frequency several solutions may be possible – then other factors can be considered, such as trying to minimize the delays of the most timing-critical signals (DQ, DQS) to reduce dependence on the possible delay vs. temperature variations (not measured yet).
Model and parameters of the input/output delay elementsProcessing of the measurement results in steps 4 and 6 involved using a delay model defined by a set of parameters and then finding the values of these parameters to best fit the measurement results.
Each data byte lane is independent from the other, so for each of the 4 groups (two for output and two for input) there are nine signals – one DQS and 8 DQ signals. Each delay consists of a 32-tap delay line with the datasheet delay of 78 ps per tap and a 5-tap delay with nominal 10 ps step. Our model represents each 32-tap delay as linear with tDQ[7:0] delays corresponding to a tap 0 and tSDQ[7:0], tSDQS – individual scale (measured in picoseconds per step). Fine delay steps turned out to be very non-uniform (in some cases even non-monotonic) so each of the 4 delay values (for 5-tap delay) is assigned an individual parameter – 4 for DQS (tFSDQS) and 32 for DQ (tFSDQ).
Procedure of measuring all 4 combinations of leading/trailing edges of the strobe and data makes it possible to calculate duty cycle for each of the 9 signals – tDQSHL (difference between time high and time low for the DQS signal) and eight tDQHL[7:0] for the similar differences for each of the data lines. Additional parameter was used to model the uncertainty of the measurement results (number of ones or zeros of the 32 samples) as a function of the delay difference from the center (corresponding to 50% of the zeros and ones). This parameter (anaScale in the program code) is measured in picoseconds and means how much the delay should be changed to switch form all 0 to all 1 (using simple piecewise linear approximation).
Parameter fitting is implemented using Levenberg-Marquardt algorithm, initial scale values use dataseeet data, initial delays are estimated using histograms of the acquired data (to separate data acquired with different integer number of clock cycles shift), other parameters are initialized to zeros. Below is a sample of the program output – algorithm converges rather quickly, getting to the remaining root mean square error (difference between the measured and modeled data) of about 10ps:
Before LMA (DQ lane 0): average(fx)= 40.929028ps, rms(fx)=68.575944ps
0: LMA_step SUCCESS average(fx)= -0.336785ps, rms(fx)=19.860737ps
1: LMA_step SUCCESS average(fx)= -0.588623ps, rms(fx)=11.372493ps
2: LMA_step SUCCESS average(fx)= -0.188890ps, rms(fx)=10.078727ps
3: LMA_step SUCCESS average(fx)= -0.050376ps, rms(fx)=9.963139ps
4: LMA_step SUCCESS average(fx)= -0.013543ps, rms(fx)=9.953569ps
5: LMA_step SUCCESS average(fx)= -0.003575ps, rms(fx)=9.952006ps
6: LMA_step SUCCESS average(fx)= -0.000679ps, rms(fx)=9.951826ps
Tables 1 and 2 summarize parameters of delay models for all input and data/strobe output signals. Of course these parameters do not describe the pure delay elements of the FPGA device, but a combination of these elements, I/O ports and PCB traces, delays in the DDR3 memory device. The BUFIO clock buffers and routing delays also contribute to the delays of the DQS input paths.
Table 1. Input delays model parameters
parameter
number of values
average
min
max
max-min
units
tDQSHL
2
4.67
-35.56
44.9
80.46
ps
tDQHL
16
-74.12
-128.03
-4.96
123.07
ps
tDQ
16
159.87
113.93
213.44
99.51
ps
tSDQS
2
77.98
75.36
80.59
5.23
ps/step
tSDQ
16
75.18
73
77
4
ps/step
tFSDQS
8
5.78
-1.01
9.88
10.89
ps/step
tFSDQ
64
6.73
-1.68
14.25
15.93
ps/step
anaScale
2
17.6
17.15
18.05
0.9
ps
I noticed the existence of these 5-tap delay elements in the utilization report of Xilinx Vivado tools – they do not seem to be documented in the Libraries Guide. I assume that the manufacturer was not very happy with their performance (the average measured value of the delay per tap turned out to be less than 7 ps so even the last tap output does not provide delay of the half of the 32-tap step, and non-uniformity of the delays makes it difficult to use in the simple hardware-based delay adjustment modules. But I like this option – it almost gives one extra bit of delay and as we are using software for delay calibration it is not a problem to have even a non-monotonic delay stage. So I would like to see this feature improved – added more taps to completely cover the full step of the coarse delay stage in the future devices, and have this nice feature documented, not hidden from the users.
Use of the internal voltage reference and the duty cycle correctionInternal reference voltage option was used in the tested circuitry because of the limited number of pins to implement a single-bank 16-bit wide memory interface, and the Xilinx datasheet limits memory clock to just 400 MHz for such configuration. Measurements show that there is a bias of -74.12ps on the duty cycle that may be caused by variation of the internal reference voltage, but the spread of the delays (123 ps) is still larger. Of course it is difficult to judge without having statistics on multiple units, but I suppose that the handicap of using internal reference is not that significant. And even 123ps is not that big as tDQHL was measured as a difference of duration high minus duration low, so if one transition edge is fixed, the other will have an error of just half of this value – less than a coarse (32-tap) delay when calibrated at 200 MHz (fine delay is possible to calibrate with 300MHz).
It would be nice to have at least a couple of bits in the delay primitives dedicated to the duty cycle correction of the delay elements that can be implemented as selective AND or OR the delay tap output with the previous one.
Kernel development for OpenEmbedded with Eclipse
Eclipse with C Development Tool (CDT) is a very powerful and feature-rich IDE for developing embedded Linux applications, such as Elphel393 camera. CDT includes CODAN — static code analysis tool which helps user to track possible problems in his code without compiling it, and Code Indexer, giving an auto-complete and code navigating (F3) features. They work independently from compiler, thus parsing the code in the same manner as compiler does is essential for producing meaningful results. As project grows, the interconnections between its parts tend to become more and more complicated, and maintaining the congruency of code processing for compiler and CODAN/Code Indexer becomes a non-trivial task. In the Internet, the most frequent recommendation for users who wish to develop Linux kernel with Eclipse is to disable CODAN feature since messy false error markers make it practically unusable. The situation becomes even worse for developers using external build tools (such as OpenEmbedded’s BitBake) as CODAN relies on output of a CDT-integrated build system to find correct way of code parsing. Anyway, embedded Linux applications usually involve kernel development, so we’ll try to find a practical approach to get the power of CODAN and Code Indexer into our hands.
Preparing the source code
I assume Poky image build environment is already set up. More info can be found here.
Main source of analysis errors are incorrect include paths, large number of unused source files which don’t contribute to build and break the index by redefining already defined symbols, and additional parameters that don’t present in a code and are transmitted to compiler via '-D' and '-include' flags. We can get all this data from build output. This will require a specific BitBake recipe and a parser script (the script is written in Python).
In Elphel, we use a specially arranged project tree for kernel development — it allows us to plug developed drivers and patches to any kernel used by BitBake with a number of symlinks. Two sets of symlinks allow BitBake to “see” developed source files while compiling the kernel and Eclipse to “see” the main kernel source code. To create this project tree, navigate to poky/ and run:
git clone https://github.com/Elphel/linux-elphel.git
Required links are described in a kernel build recipe and created by BitBake during the ‘unpack’ task. Build is needed to produce all automatically generated header files.
. ./oe-init-build-env
bitbake linux-xlnx -c clean -f
bitbake linux-xlnx -c unpack -f
bitbake linux-xlnx -f
Setting up the Eclipse project
Created project tree already contains prepared project settings file (.cproject). In this blog I’ll give a summary of those settings.
Run Eclipse. Some additional heap memory may be required for indexing the kernel source:
./eclipse -vmargs -Xmx4G
- File → New → C Project
- Name = linux-elphel (this is hard-coded in a parser script so if you want to change it, edit the script as well)
- Uncheck “Use default location”
- Location = path to linux-elphel/ project directory
- Project type = Makefile project → Empty Project
- Toolchain = Linux GCC
- [Next] → Advanced Settings (OK to overwrite)
- C/C++ General → Preprocessor Include Paths → Entries → GNU C → CDT User Settings
- [Add...] → Select “Preprocessor macros file” → linux/include/generated/autoconf.h → [OK]
- [Add...] → Select “Preprocessor macros file” → linux/include/linux/compiler.h → [OK]
- C/C++ General → Indexer
- Check “Enable project specific setttings”
- Check “Enable indexer”
- Uncheck “Index source files not included in the build”
- Uncheck “Index unused headers”
- Check “Index header variants”
- Uncheck “Index source and header files opened in editor”
- Uncheck “Allow heuristic resolution of includes”
- Set size of files to be skipped >100MB (effectively disabling this feature)
- Uncheck all “Skip…” options
- C/C++ General → Paths and symbols → Includes → GNU C → [Add...] → [Workspace] → /linux-elphel/linux/include → [OK] → [Ok]
- C/C++ General → Paths and symbols → Source Location → [Add Folder...] → select linux/ → [OK]
- In the same window delete default source location entry (/linux-elphel)
- C/C++ General → Paths and symbols → Symbols → GNU C → [Add...] → Name=__GNUC__, value=4 → [OK]
- C/C++ General → Preprocessor Include Paths → Providers → Uncheck all except CDT User Setting Entries and CDT Managed Build Setting Entries
- [OK] to close Advanced Settings window → Finish.
The project is created. Close Eclipse for now.
Running the parser
Download the parser script into poky/build/ directory:
git clone https://github.com/Elphel/kernel-bitbake-parser.git
Build kernel with specific set of flags (it’ll take a while) and parse the output:
export _MAKEFLAGS="-s -w -j1 -B KCFLAGS='-v'"
export BB_ENV_EXTRAWHITE="$BB_ENV_EXTRAWHITE _MAKEFLAGS"
bitbake linux-xlnx -c clean -f
bitbake linux-xlnx -c compile -v -f|python3 ./kernel-bitbake-parser/kbparse.py
The output consists of 4 sections — Define statements, Include paths, Source paths and Extra include files. First 3 of them are formatted as XML tags allowing to copy’n'paste them directly into respective nodes of a .cproject file. Script will attempt to automatically modify .cproject file as well. Extra includes have to be manually added from Eclipse. (C/C++ General → Preprocessor Include Paths → Entries → GNU C → CDT User Settings → [Add...] → Select “Include file” → Copy the path from parser output → [OK])
Run Eclipse:
./eclipse -vmargs -Xmx4G
Project → C/C++ Index → Rebuild.
The result is less than 0.005% of unresolved symbols (this can be seen from the Error Log, Window → Show view → Other… → Error Log) and no error markers from CODAN.
Trying out KiCAD
Introduction
{kind=link}
Teardrops in KiCAD
We, at Elphel, are currently using proprietary software for schematic and PCB development and thus are not able to provide our customers with the “real” source files of our designs – pdf and gerber files only. Being free software and open hardware oriented company we would like to replace this software with open source analogues but were not able to accomplish this due to various limitations and inconveniences in design work-flow. We follow the progress in such projects as gEDA and KiCAD and made another attempt to use one them in our work. KiCAD seems to be the most promising design suite considering recent CERN contribution and active community support. I tried to design a simple element, a flexible printed circuit cable, using KiCAD and found out that the PCB design program lacks such useful feature as teardrops.
What are teardropsTeardrops are often used to create mechanically stronger connections between tracks and pads/vias to prevent drill breakout during board manufacturing. This is particularly valuable when the design objects are small, as it was in my case. The figures below explain the problem:
{kind=link}
Fig. 1
{kind=link}
Fig. 2
{kind=link}
Fig. 3
{kind=link}
Fig. 4
Fig. 1 shows perfectly aligned drill hole but the final result (as on Fig. 2) can be far from perfect because of drill tool wandering or board stack misalignment during manufacturing. Relaxing specification or allowing drill breakout along the hole perimeter, as on Fig. 4, is not always possible. Adding teardrops (Fig. 3) in such cases is a good option.
The images below show misaligned drill holes on manufactured PCBs:
{kind=link}
{kind=link}
The great advantage of any open source project is the possibility to add any required feature or fix bugs on your our. I cloned KiCAD repository and dived into the source code trying to add mock up implementation of teardrops. It took some time to get acquainted with class hierarchies and internal structures. Finally, I added new option to “Tools” menu which adds teardrops to currently selected track. Two types of teardrops are implemented by the moment: curved (github link) and straight (github link). The process of selection and results are shown on the screenshots:
{kind=link}
The straight teardrops are composed of two segments connecting tracks and vias. The curved teardrops are actually approximated with several short segments as KiCAD does not allow to place arcs on copper layers. There are several intentional limitations in current implementation:
- teardrops are created for vias only
- DRC rules are not taken into consideration during calculations
- the ends of selected track must coincide with via center
- no user adjustable settings
These limitations are caused by test nature of my source code and at the same time they define the fields of further development. The result obtained is good enough to be used in real applications.
Links:https://www.flickr.com/photos/andresrueda/
https://www.flickr.com/photos/creative_stock/
https://github.com/Elphel/kicad-source-mirror
More lenses tested: Evetar N123B05425W vs. Sunex DSL945D
We just tested two samples of Evetar N123B05425W lens that is very similar to Sunex DSL945D described in the previous post.
Lens Specifications
Sunex DSL945D
Evetar N123B05425W
Focal length
5.5mm
5.4mm
F#
1/2.5
1/2.5
IR cutoff filter
yes
yes
Lens mount
M12
M12
image format
1/2.3
1/2.3
Recommended sensor resolution
10Mpix
10MPix
Both lenses are specified to work with 10 megapixel sensors, so it is possible to compare “apples to apples”. This performance compaison is based only on our testing procedure and does not involve any additional data from the lens manufacturers, the lens samples were randomly selected from the purchased devices. Different applications require different features (or combination of features) of the lens, and both lenses have their advantages with respect to the other.
Sunex lens has very low longitudinal chromatic aberration (~5μm) as indicated on “Astigmatism” (bottom left) graphs, it is well corrected so both red and blue curves are on the same side of the green one. Evetar lens have very small difference between red and green, but blue is more than 15 μm off. My guess is that the factory tried to make the lens that can work in “day/night” applications and optimized design for visible and infrared spectrum simultaneously. Sacrificing infrared (it anyway has no value in high resolution visible light applications) at the design stage could improve performance of this already very good product.
Petzval field curvature of the DSL945D is slightly better than that of the N123B05425W, astigmatism (difference between the sagittal and the tangential focal shift for the same color) is almost the same with maximum of 18 μm at ~2 mm from the image center.
Center resolution (mtf50% is shown) of the DSL945D is higher for each color, but only in the center. It drops for peripheral areas much quicker than the resolution of the N123B05425W does. Evetar lens has only sagittal (radial) resolution for blue component dropping below 100 lp/mm according to our measurements, and that gives this lens higher full-field weighted resolution values (top left plot on each figure).
Lens testing dataThe graphs below and the testing procedure are described in the previous post. Solid lines correspond to the tangential and dashed – to the sagittal components for the radial aberration model, point marks account for the measured parameter variations in the different parts of the lenses at the same distance from the center.
Sunex DSL945D{kind=link}
Fig.1 Sunex SLR945D sample #1020 test results. Spreadsheet link.
Evetar N123B05425W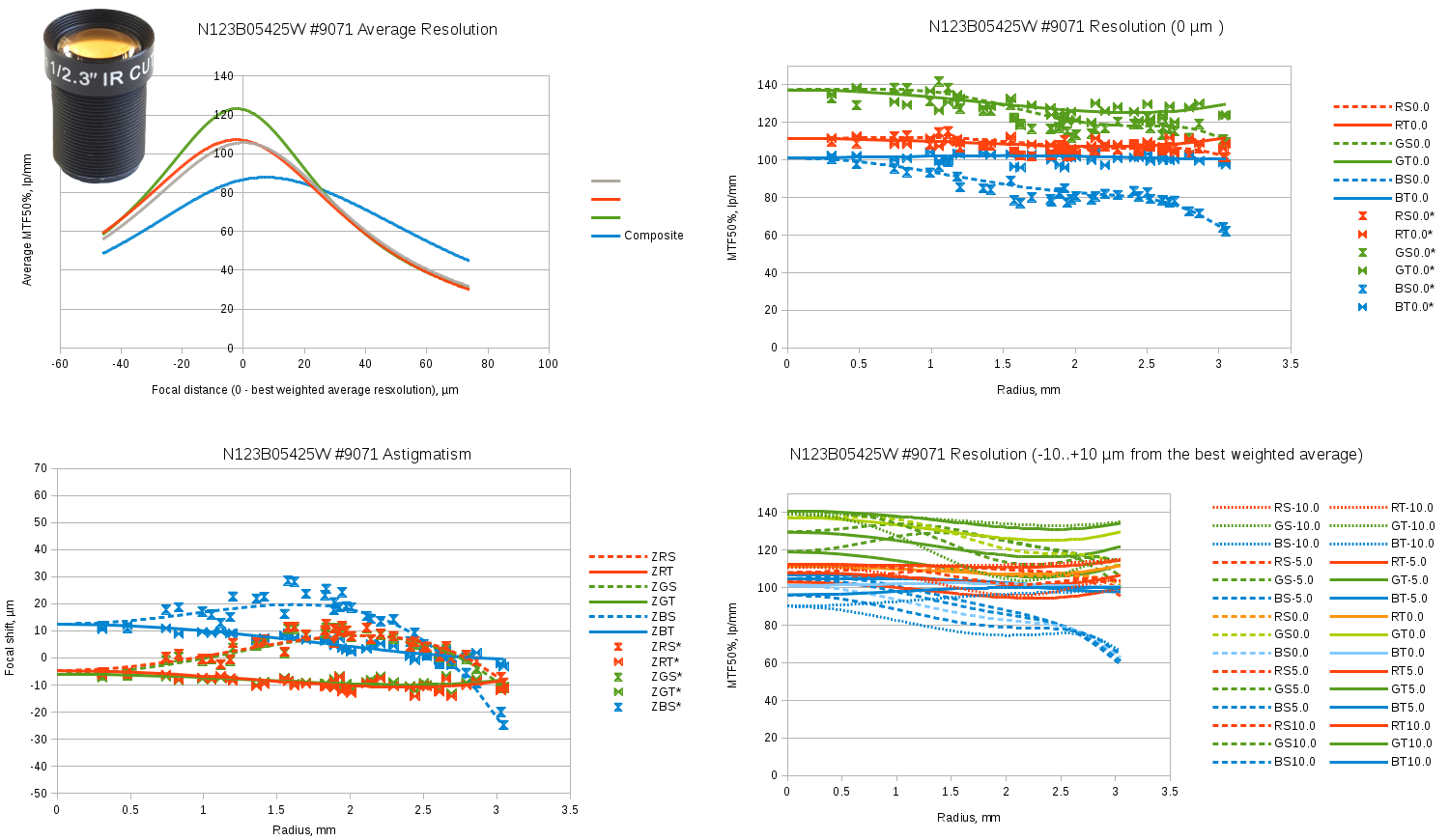{kind=link}
Fig.2 Evetar N123B05425W sample #9071 test results. Spreadsheet link.
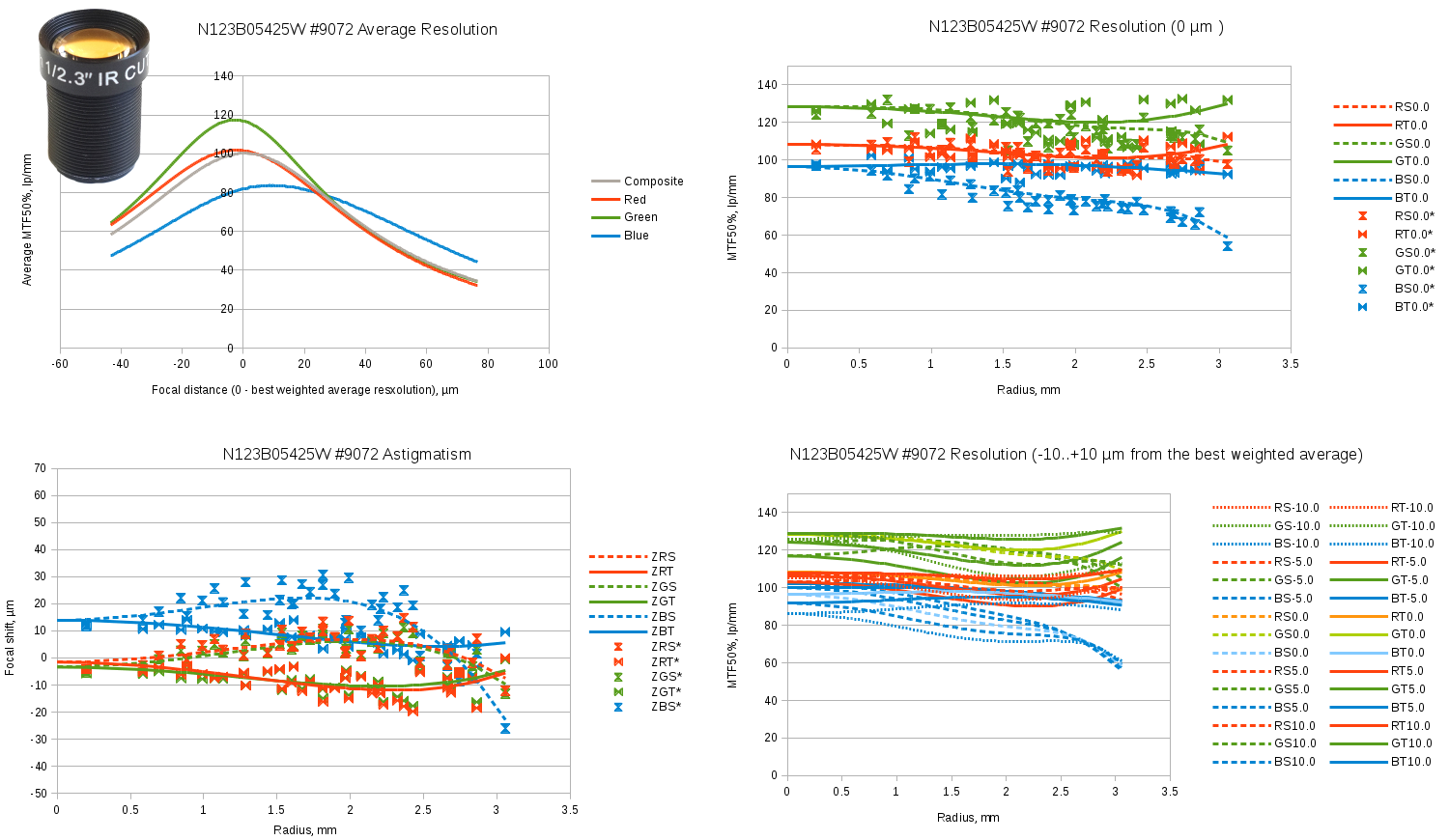{kind=link}
Fig.3 Evetar N123B05425W sample #9072 test results. Spreadsheet link.
Lens testing at Elphel
We were measuring lens performance since we’ve got involved in the optical issues of the camera design. There are several blog posts about it starting with "Elphel Eyesis camera optics and lens focus adjustment". Since then we improved methods of measuring Point Spread Function (PSF) of the lenses over the full field of view using the target pattern modified from the standard checkerboard type have better spatial frequency coverage. Now we use a large (3m x 7m) pattern for the lens testing, sensor front end (SFE) alignment, camera distortion calibration and aberration measurement/correction for Eyesis series cameras.
{kind=link}
Fig.1 PSF measured over the sensor FOV – composite image of the individual 32×32 pixel kernels
So far lens testing was performed for just two purposes – select the best quality lenses (we use approximately half of the lenses we receive) and to precisely adjust the sensor position and tilt to achieve the best resolution over the full field of view. It was sufficient for our purposes, but as we are now involved in the custom lens design it became more important to process the raw PSF data and convert it to lens parameters that we can compare against the simulated achieved during the lens design process. Such technology will also help us to fine-tune the new lens design requirements and optimization goals.
The starting point was the set of the PSF arrays calculated using images acquired from the the pattern while scanning over the range of distances from the lens to the sensor in small increments as illustrated on the animated GIF image Fig.1. The sensor surface was not aligned to be perpendicular to the optical axis of the lens before the measurement -each lens and even sensor chip has slight variations of the tilt and it is dealt with during processing of the data (and during the final alignment of the sensor during production, of course). The PSF measurement based on the repetitive pattern gives sub-pixel resolution (1.1μm in our case with 2.2μm Bayer mosaic pixel period – 4:1 up-sampled for red and blue in each direction), but there is a limit on the PSF width that the particular setup can handle. Too far out-of-focus and the pattern can not be reliably detected. That causes some artifacts on the animations made of the raw data, these PSF samples are filtered during further processing. In the end we are interested in lens performance when it is almost in perfect focus, so scanning too far away does not provide much of the practical value anyway.
Acquiring PSF arrays{kind=link}
Fig. 2 Pattern grid image
Each acquired image of the calibration pattern is split into color channels (Fig.2 shows the pattern raw image – if you open the full version and zoom in you can see that there is 2×2 pixel periodic structure) and each channel is processed separately, colors are combined back on the images only for illustrative purposes. Of the full image the set of 40 samples (per color) is processed, each corresponding to 256×256 pixels of the original image.
Fig. 3 shows these sample areas with windowing functions applied (this reduces artifacts during converting data to frequency domain). Each area is up-sampled to 512×512 pixels. For red and blue channels only one in 4×4=16 pixels is real, for green – two of 16. Such reconstruction is possible as multiple periods of the pattern are acquired (more description is available in the earlier blog post). The size of the samples is determined by a balance of the sub-pixel resolution (the larger the area – the better) and resolution of the PSF measurements over the FOV. It is also difficult to process large areas in the case of higher lens distortions, because the calculated “ideal” grid used for deconvolution had to be curved to precisely match to the acquired image – errors would widen the calculated PSF.
{kind=link}
Fig. 3 Pattern image split into 40 regions for PSF sampling
The model pattern is built by first correlating each pattern grid node (twisted corner of the checkerboard pattern) over smaller area that still provides sub-pixel resolution, and then calculating the second degree polynomial transformation of the orthogonal grid to match these grid nodes. The calculated transformation is applied to the ideal pattern and result is used in deconvolution with the measured data producing the PSF kernels as 32×32 pixel (or 35μm x 35μm) arrays. These arrays are stored as 32-bit multi-page TIFF images arranged similarly to the animated GIF on Fig.1 making it easier to handle them manually. The full PSF data can be used to generate MTF graphs (and it is used during camera aberration correction) but for the purpose of the described lens testing each PSF sample is converted to just 3 numbers describing ellipse approximating PSF full width half maximum (FWHM). These 3 numbers are reduced to just two when the lens center is known – sagittal (along the radius) and tangential (perpendicular to the radius) projections. The lens center is determined either from finding the lens radial distortion center using our camera calibration software, or it can be found as a pair of variable parameters during the overall fitting process.
Data we collected in earlier procedureIn our previous lens testing/adjustment procedures we adjusted tilt of the sensor (it is driven by 3 motors providing both focal distance and image plane tilt control) by balancing vertical to horizontal PSF FWHM difference in both X and Y directions and then finding the focal distance providing the best “averaged” resolution. As we need good resolution over the full FOV, not just in the center, we are interested in maximizing the worst resolution over the FOV. As a compromise we currently use a higher (fourth) power of the individual PSF components width (horizontal and vertical) over all FOV samples, average the results and extract the fourth root. Then mix results for individual colors with 0.7:1.0:0.4 weights and consider it as a single quality parameter value of the lens (among the samples of the same lens model). There are different aberration types that widen the PSF of the lens-sensor combination, but they all result in degradation of the result image “sharpness”. For example the lens lateral chromatic aberration combined with the spectral bandwidth of the sensor color filter array reduces lateral resolution of the peripheral areas compared to the monochromatic performance presented on the MTF graphs.
Automatic tilt correction procedure worked good in most cases, but it depended on a particular lens type characteristics and even sometimes failed for the known lenses because of the individual variations between lens samples. Luckily it was not a production problem as this happened only for lenses that differed significantly from the average and they also failed the quality test anyway.
Measuring more lens parametersTo improve the robustness of the automatic lens tilt/distance adjustment of the different lenses, and for comparing lenses – actual ones, not just the theoretical Zemax or OSLO simulation plots we needed more processing of the raw PSF data. While building cameras and evaluating different lenses we noticed that it is not so easy to find the real lens data. Very few of the small format lens manufacturers post calculated (usually Zemax) graphs for their products online, some other provide them by request, but I’ve never seen the measured performance data of such lenses so far. So far we measured small number of lenses – just to make sure the software works (the results are posted below) and we plan to test more of the lenses we have and post the results hoping they can be useful for others too.
The data we planned to extract from the raw PSF measurements includes Petzval curvature of the image surface including astigmatism (difference between sagittal and tangential surfaces) and resolution (also sagittal and tangential) as a function of the image radius for each of the 3 color components, measured at different distances from the lens (to illustrate the optimal sensor position). Resolution is measured as spot size (FWHM), on the final plots it is expressed as MTF50 in lp/mm – the relation is valid for Gaussian spots, so for real ones it is only an approximation: MTF50≈2*ln2π*PSFFWHM. Reported results are not purely lens properties as they depend on the spectral characteristics of the sensor, but on the other hand, most lens users attach them to some color sensor with the same or similar spectral characteristics of the RGB micro-filter array as we used for this testing.
Consolidating PSF measurementsWe planned to express PSF size dependence (individually for 2 directions and 3 color channels) on the distance from the sensor as some functions determined by several parameters, allow these parameters to vary with the radius (distance from the lens axis to the image point) and then use Levenberg-Marquardt algorithm (LMA) to find the values of the parameters. Reasonable model for such function would be a hyperbola:
(1) f(z)=(a*(z-z0))2+r02
where z0 stands for the “best” focal distance for that sample point/component, a defines asymptotes (it is related to the lens numeric aperture) and r0 defines the minimal spot size. To match shift and asymmetry of the measured curves two extra terms were added:
(2) f(z)=(a*(z-z0))2+(r0-s)2 +s+t*a*(z-z0)
New parameter s adjusts the asymptotes crossing point above zero and t “tilts” the function together with the asymptotes. To make the parameters less dependent on each other the whole function was shifted in both directions so varying tilt t does not change position and value of the minimum:
(3) f(z)=(a*(z-z0-zcorr))2+(r0-s)2 +s+t*a*(z-z0-zcorr)-fcorr
where (solved by equating the first derivative to zero:dfdz=0):
(4) zcorr=(r0-s)*ta*1-t2
and
(5) fcorr=(a*zcorr)2+(r0-s)2-t*a*zcorr-(r0-s)
Finally I used logarithms of a, r0, s and arctan(t) to avoid obtaining invalid parameter values from the LMA steps if started far from the optimum, and so to increase the overall stability of the fitting process.
There are five parameters describing each sample location/direction/color spot size function of the axial distance of the image plane. Assuming radial model (parameters should depend only on the distance from the lens axis only) and using polynomial dependence of each of the parameter on the radius that resulted in some 10-20 parameter per each of the direction/color channel. Here is the source code link to the function that calculates the values and partial derivatives for the LMA implementation.
Applying radial model to the measured data{kind=link}
Fig.4 PSF sample points naming
{kind=link}
Fig.5 Fitting individual spot size functions to radial aberration model. Spreadsheet link
When I implemented the LMA and tried to find the best match (I was simultaneously adjusting the image plane tilt too) for the measured lens data, the residual difference was still large. Top two plots on Fig.5 show sagittal and tangential measured and modeled data for eight location along the center horizontal section of the image plane. Fig.4 explains the sample naming, linked spreadsheet contains full data for all sample locations and color/direction components. Solid lines show measured data, dashed – approximation by a radial model described above.
The residual fitting errors (especially for some lens samples) were significantly larger than if each sample location was fitted with individual parameters (the two bottom graphs on Fig.5). Even the best image plane tilt determined for sagittal and tangential components (if fitted separately) produced different results – one one lens the angle between the two planes reached 0.4°. The radial model graphs (especially for Y2X6 and Y2X7) show that the sagittal and tangential components are “pulling” the result in opposite directions It became obvious that the actual lenses can not be fully characterized in the terms of just the radial model as used for simulation of the designed lenses, the deviations of the symmetrical radial model have to be accounted for too.
Adjustment of the model parameters to accommodate per-location variationsI modified the initial fitting program to allow individual (per sample location) adjustment of the parameter values, adding cost of correction variation from zero and/or from the correction values of the same parameter at the neighbors sites. Sum of the squares of the corrections (with balanced weights) was added to the sum of the squares of the differences between the measured PSF sizes and the modeled ones. This procedure requires that small parameter variations result in small changes of the functions values, that was achieved by the modeling function formula modification as described above.
Lenses testedNew program was tested with 7 lens samples – 5 of them were used to evaluate individual variations of the same lens model, and the two others were different lenses. Each result image includes four graphs:
- Top-left graph shows weighted average resolution for each individual color and the combination of all three. Weighted average here processes the fourth power of the spot size at each of the 40 locations in both (sagittal and tangential) directions so the largest (worst) values have the highest influence on the result. This graph uses individually fitted spot size functions
- Bottom-left graph shows Petzval curvature for each of the 6 (2 directions of 3 colors) components. Dashed lines show sagittal and solid lines – tangential data for the radial model parameters, data point marks – the individually adjusted parameters, so same radius but different direction from the lens center results in the different values
- Top-right graph shows the resolution variation over radius for the plane at the “best” (providing highest composite resolution) distance from the lens, lines showing radial model data and marks – individual samples
- Bottom-right graph shows a family of the resolution functions for -10μm (closest to the lens), -5μm, 0μm, +50μm and +10μm positions of the image plane
Evetar N125B04518W is our “workhorse” lens used in Eyesis cameras. 1/2.5″ format lens, focal length=4.5mm, F#=1.8. It is a popular product, and many distributors sell this lens under their own brand names. One of the reasons we are looking for the custom lens design is that while this lens has “W” in the model name suffix meaning “white” (as opposed to “IR” for infrared) it is designed to be a “one size fits all” product and the only difference is addition of the IR cutoff filter at the lens output. This causes two problems for our application – reduced performance for blue channel (and high longitudinal chromatic aberration for this color) and extra spherical aberration caused by the plane-parallel plate of the IR cutoff filter substrate. To mitigate the second problem we use non-standard very thin – just 0.3mm filters.
Below are the test results for 5 randomly selected samples of the batch of the lenses with different performance.
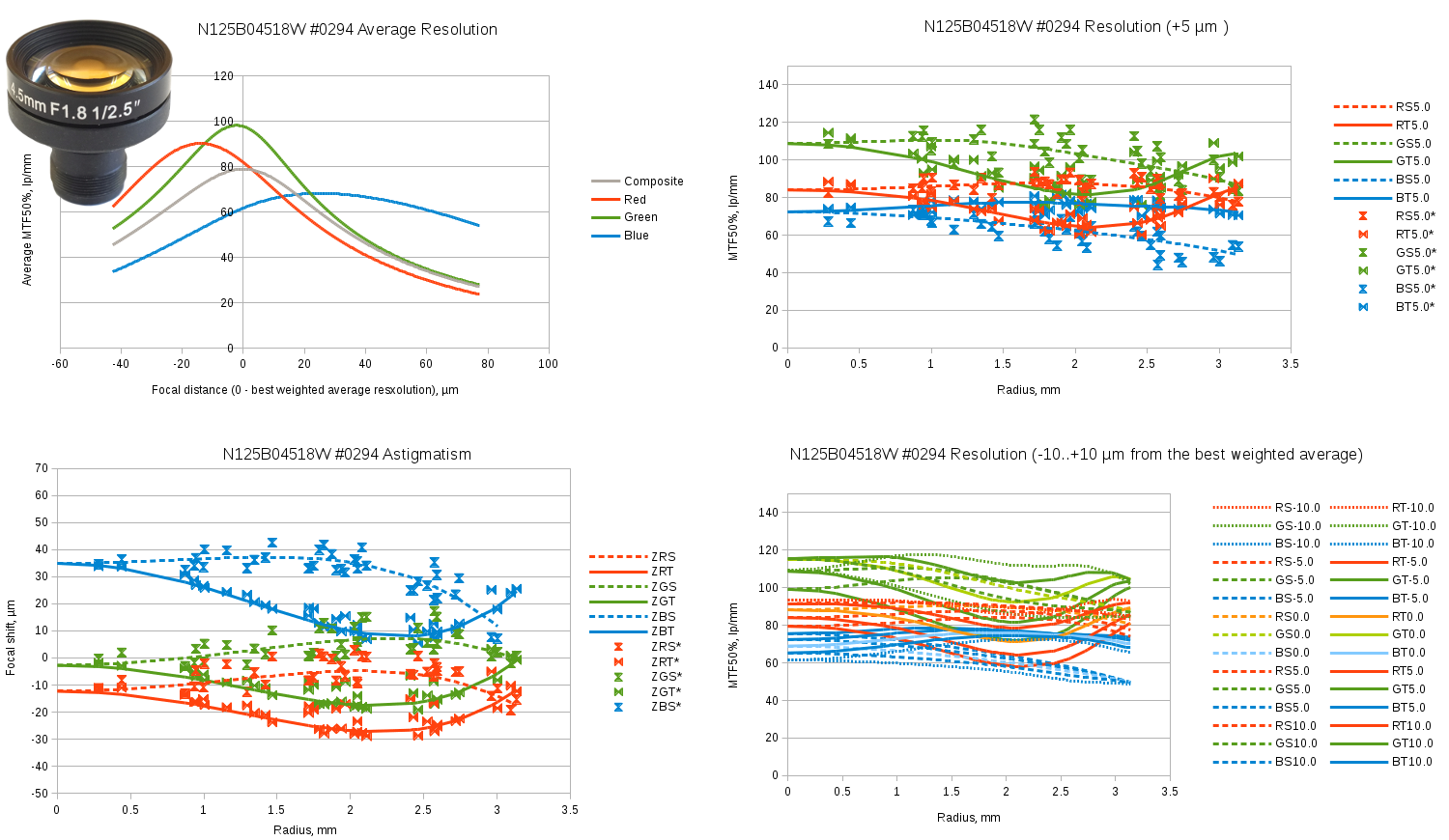{kind=link}
Fig.6 Evetar N125B04518W sample #0294 test results. Spreadsheet link.
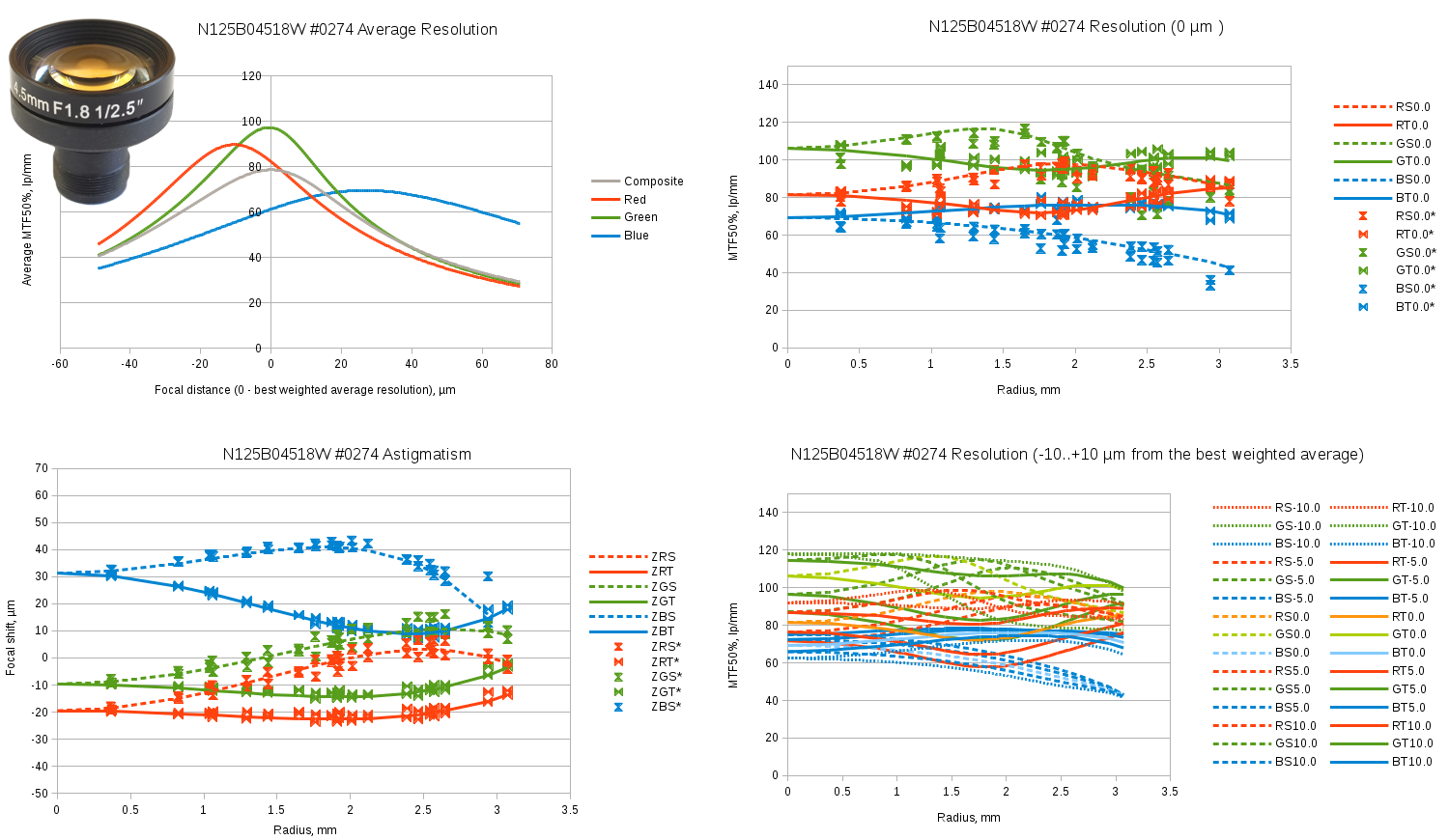{kind=link}
Fig.7 Evetar N125B04518W sample #0274 test results. Spreadsheet link.
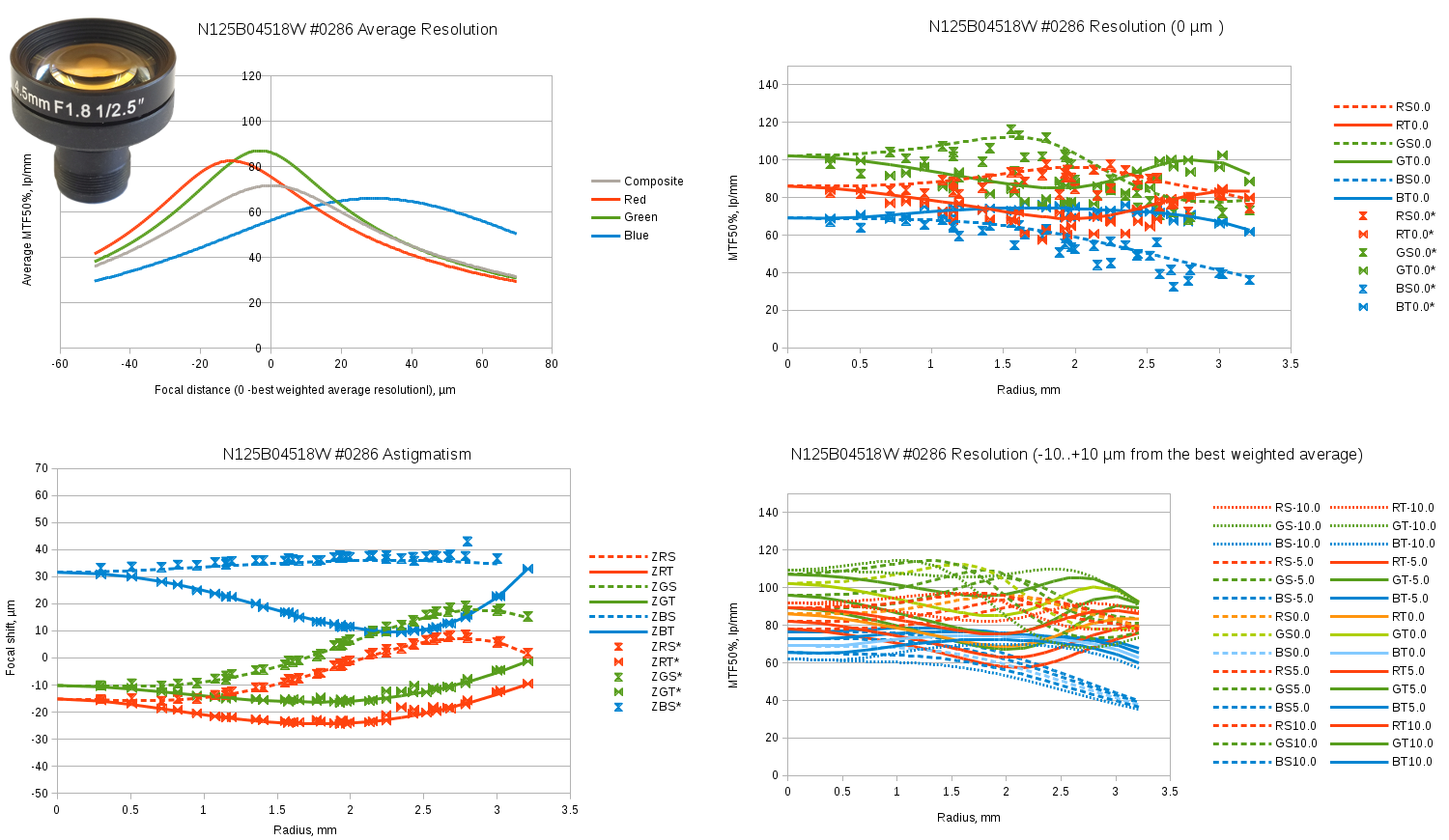{kind=link}
Fig.8 Evetar N125B04518W sample #0286 test results. Spreadsheet link.
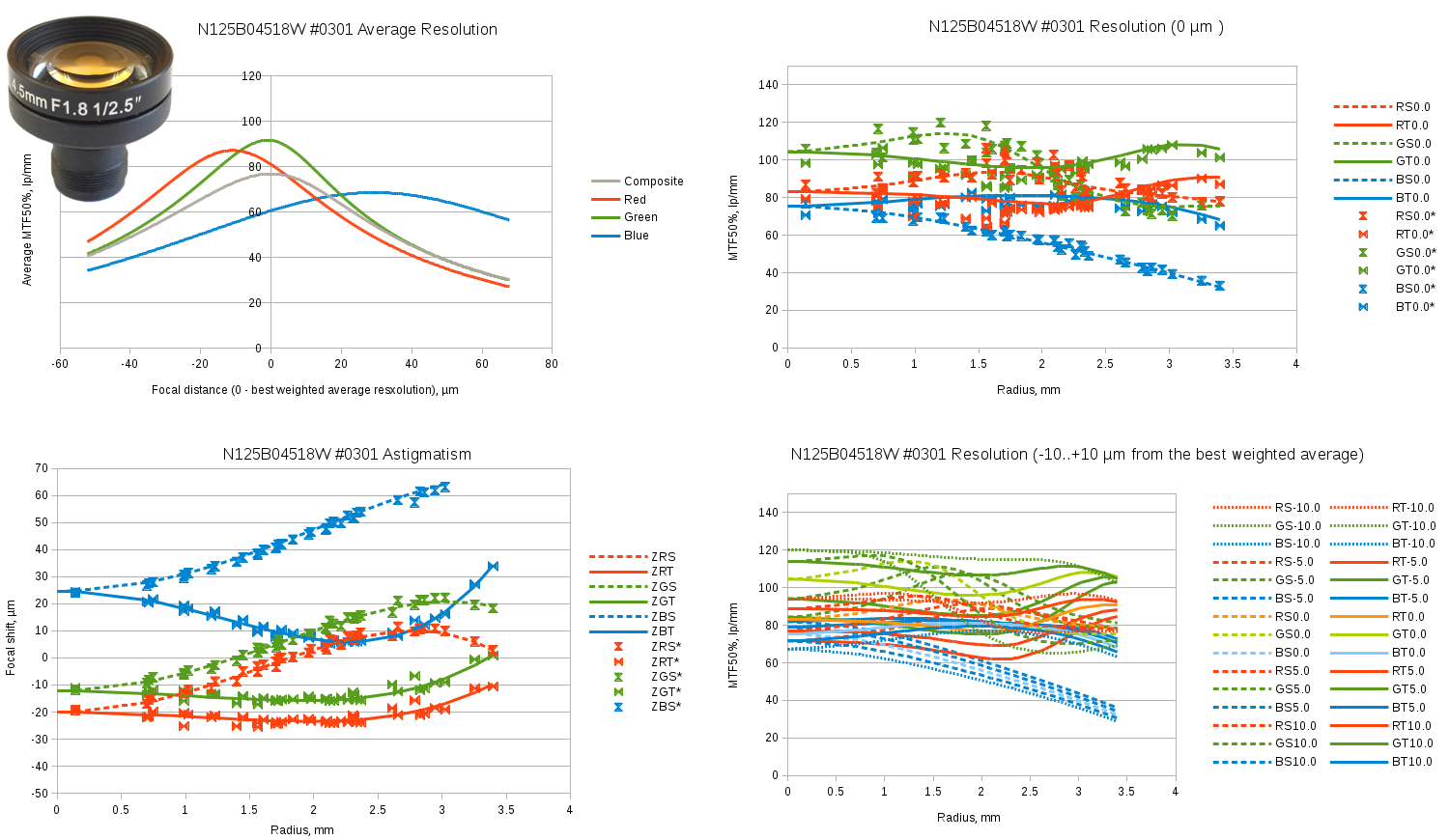{kind=link}
Fig.9 Evetar N125B04518W sample #0301 test results. Spreadsheet link.
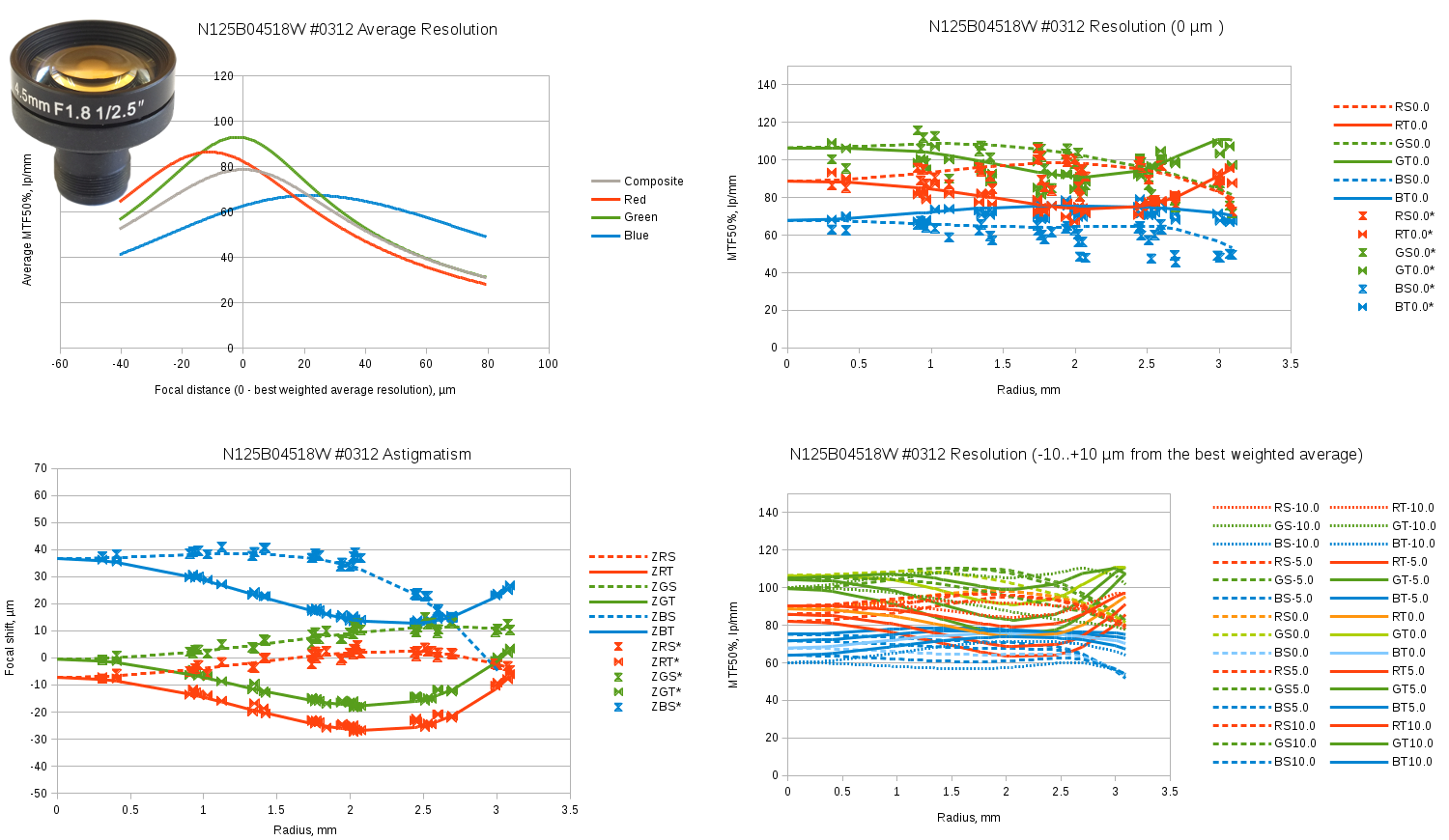{kind=link}
Fig.10Evetar N125B04518W sample #0312 test results. Spreadsheet link.
Evetar N125B04530W High resolution 1/2.5″ f=4.5mm, F#=3.0 lens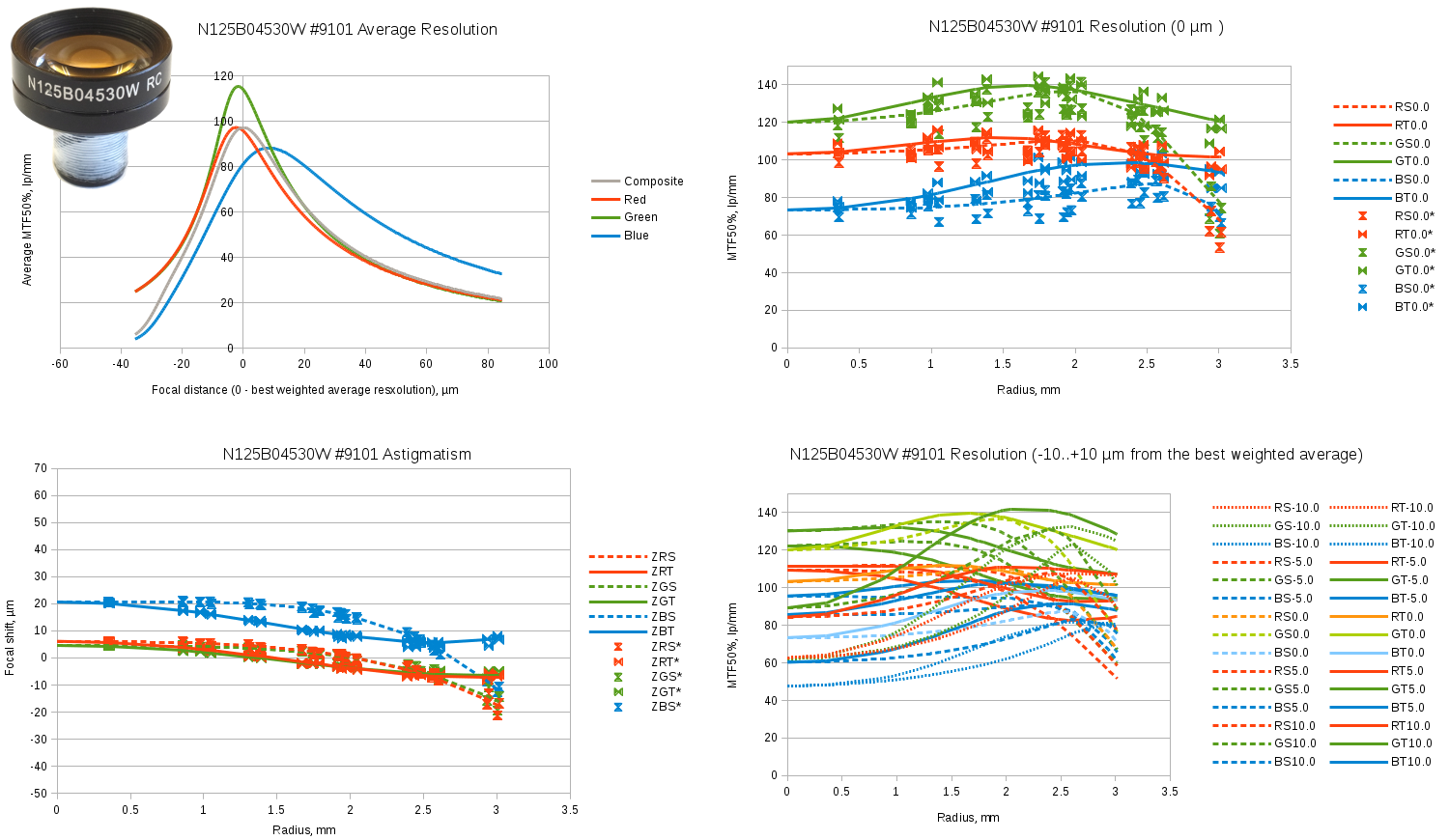{kind=link}
Fig.11 Evetar N125B04530W sample #9101 test results. Spreadsheet link.
Sunex DSL945DSunex DSL945D – compact 1/2.3″ format f=5.5mm F#=2.5 lens. Datasheet says “designed for cameras using 10MP pixel imagers”. The sample we tested has very high center resolution, excellent image plane flatness and low chromatic aberrations. Unfortunately off-center resolution degrades with the radius rather fast.
Fig.12 Sunex SLR945D sample #1020 test results. Spreadsheet link.
Software usedThis project used Elphel plugin for the popular open source image processing program ImageJ with new classes implementing the new processing described here. The results were saved as text data tables and imported in free software LibreOffice Calc spreadsheet program to create visualization graphs. Finally free software Gimp program helped to combine graphs and create the animation of Fig.1.
Optimization Intermediate Results
Description
FieldCurvature(), LateralColor(), LongSpherical() and Coma() functions are defined in a ccl script found here – they use OSLO’s built in functions to get the data.
FY – fractional (in OSLO) pupil coordinate – 0 in the center, 1.0 – the edge (at the aperture stop)
FBY – fractional (in OSLO) image height (at the image plane)
NA – numeric aperture Field Curvature (1)
Running OSLO’s optimization has shown that having a single operand defined is probably not enough. During the optimization run the program computes the derivative matrix for the operands and solves the least squares normal equations. The iterations are repeated with various values of the damping factor in order to determine the optimal value of the damping factor.
So, extra operands were added to split the initial error function – each new operand’s value is a contribution to the spot size (blurring) calculated for each color, aberration and certain image heights. See Fig.1 for formulas.
{kind=link}
Fig.1 Extra Operands
FieldCurvature(), LateralColor(), LongSpherical() and Coma() functions are defined in a ccl script found here – they use OSLO’s built in functions to get the data.
FY – fractional (in OSLO) pupil coordinate – 0 in the center, 1.0 – the edge (at the aperture stop)
FBY – fractional (in OSLO) image height (at the image plane)
NA – numeric aperture Field Curvature (1)
3 reference wavelengths, 7 image plane points (including center) and sagittal & tangential components make up 42 operands total affecting field curves shapes and astigmatism. To get the contribution to the spot size one need to multiply the value by Numerical Aperture (NA). NA is taken a constant over the full field.
Lateral Color (2)There are 3 bands the pixels are sensitive to – 510-560, 420-480 and 585-655 nm. The contribution to the spot size is then calculated for each band and 6 image plane points – there’s neither central nor tangential component – 18 operands total.
Longitudinal Spherical (3)The spot size contribution is calculated for the 3 reference wavelengths and 7 points at the aperture stop (including center). The tangential and sagittal components are equal, thus there are 42 operands.
Coma (4)It doesn’t have a huge impact on the optimization but it was still added for some control. The operands are calculated for 3 wavelengths and 6 image plane points – adds up 18 extra operands.
See Fig.2-5. All of the curvatures and thicknesses were set to variables, except for the field flattener and the sensor’s cover glass. The default OSLO’s optimization method was used – Dump Least Squared (DLS).
Parameter
Comments
Field Curvature
decreased from 20um to 5 um over the field
Astigmatism
decreased max(T-S) from ~15um to ~2.5 um
Chromatic Focal Shift
almost no changes
Lateral Color
almost no changes
Longitudinal Spherical
got better in the middle and worse in the edge
Resolution
somewhat insignificantly improved
Tried to vary the glasses but this didn’t lead to anything good – it tends to make the front surface extremely thin.
This might be the best(?) what can be achieved with the current curvatures-thicknesses (and glasses) configuration. Spherical aberration seem to contribute the most at the current f/1.8. What would be the next step?
- It’s always possible to go down to f/2.0-f/2.5. But we would keep the aperture as wide as possible.
- Add extra elements(s)?
- Where? Make changes closer to the surfaces that affect spherical aberration the most?
- Make up extra achromatic doublet(s)?
- Where? Make changes closer to the surfaces that affect spherical aberration the most?
- Introduce aspheric surface(s)?
- Plastic or glass? Some guidlines suggest to place glass close to the aperture stop and plastic – away. At the same time, “a surface close to the aperture stop tend to affect or benefit spherical aberration, surfaces located further from the stop can help minimize some or all of the off-axis aberrations such as coma and astigmatism”:
- Glass
- Where? Make changes to the surfaces that affect spherical aberration the most?
- One of the surfaces of the achromatic doublet?
- Plastic
- Where? Place a plano-aspheric element (flat front, aspheric back) at locations wheres rays are (almost) parallel? The thermal expansion might not affect the performance very much.
- Plano-aspheric element in the front of the lens?
- Aspheric surface on the achromatic doublet?
- As thin as possible? How thin can it be?
- Make the element after the doublet plano-aspheric?
- Glass
Other questions:
- Are there glass-plastic (glass-polymer? hybrid?) aspheric achromatic doublets available?
- Is it possible to glue a thin plastic aspherics on a glass element (like a contact lens)?
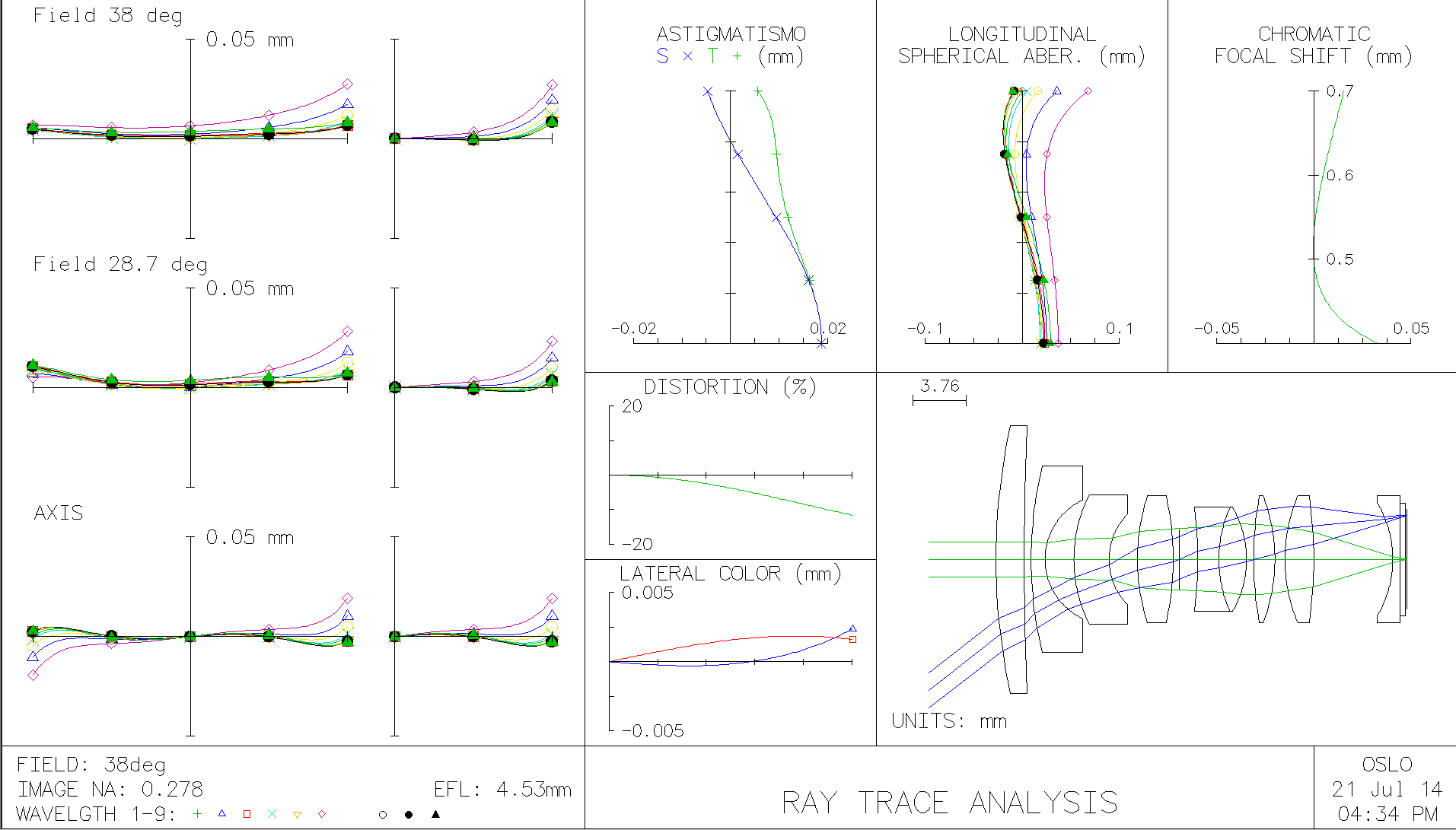{kind=link}
Fig.2 Before
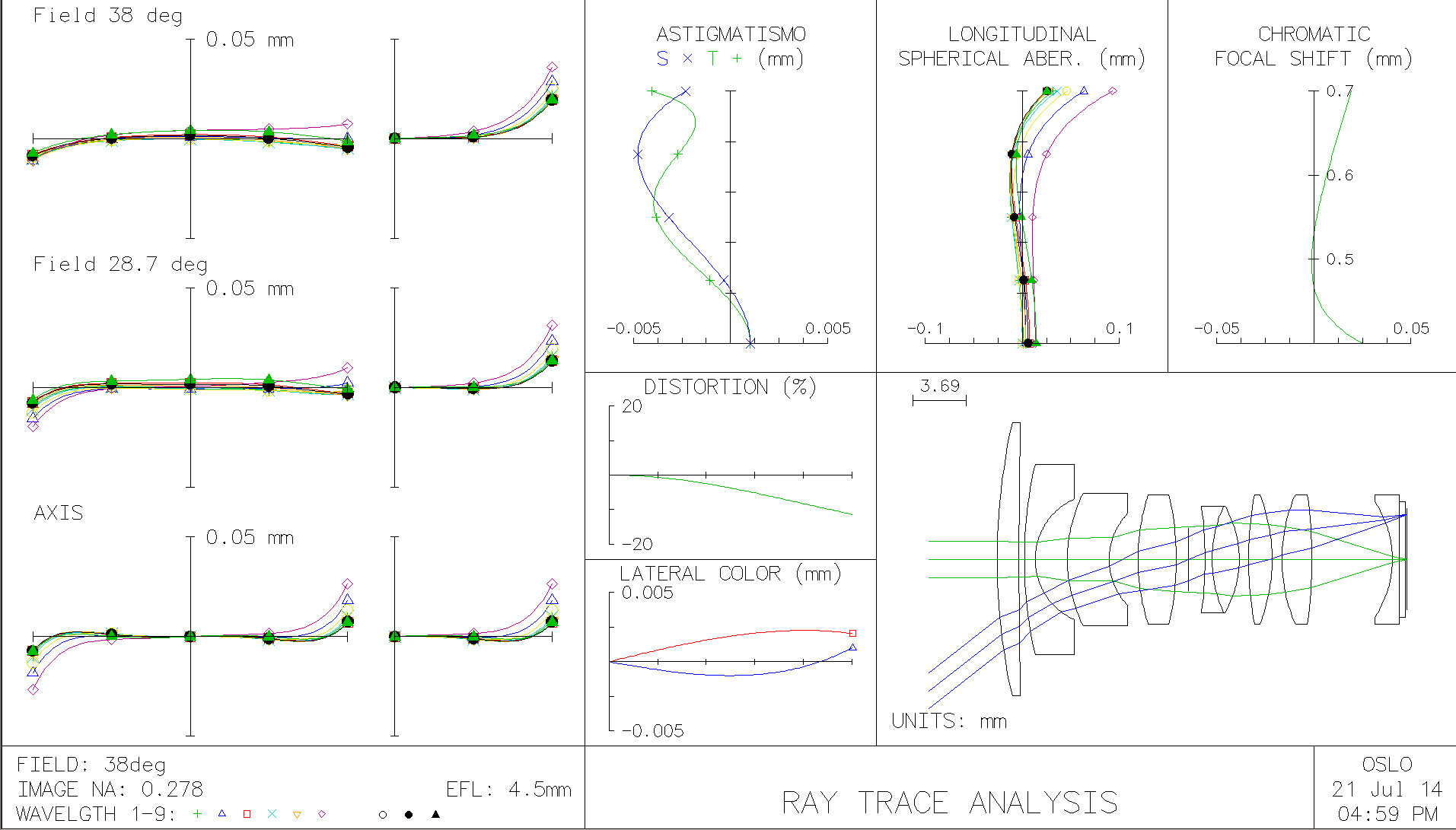{kind=link}
Fig.3 After
{kind=link}
Fig.4 Before. MTF(green)
{kind=link}
Fig.5 After. MTF(green)
Defining Error Function for Optical Design optimization (in OSLO)
Description
The Error Function calculates the 4th root of the average of the 4th power spot sizes over several angles of the field of view.
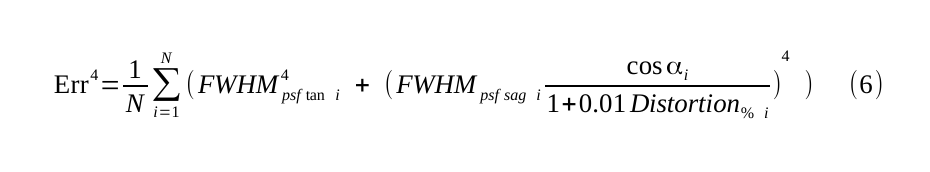{kind=link}
{kind=link}
Fig.1 Pixel’s quantum efficiency
{kind=link}
Fig.2 Example of pixel’s sensitivity range
The function takes into account:
- Pixels’ sensitivity to a band rather than a single wavelength (Fig.1). It negatively affects the sagittal component of the Point Spread Function (PSF).
- One of the goals is the uniform angular resolution and applies the corresponding coefficients to the sagittal component. The angular resolution increases with the field angle increase and degrades with negative distortion amount increase with the field angle increase
{kind=link}
Fig.3 Formulas 1-5
- If PSF shape is approximated with a Gauss function (Fig.2) (in OSLO actual PSF shapes’s data can be extracted but anyways) then the sagittal PSF for a range of wavelengths will be a Gauss function as well with its Full Width Half Maximum (FWHM) calculated using (5) (Fig.3). FWHM is the spot size.
- With a known frequency for the Modulation Transfer Function (MTF) at the value of 1/2 level FWHM for a single wavelength is calculated with (1)-(4) (Fig.3)
- The final Error Function is shown in (6) (Fig.4). Its value is set as a user-defined operand for minimization (note: the value does not tend to zero).
- The 4th power is used to be able to improve the worst parameters in the first place
{kind=link}
Fig.4 Error Function
Data- Distortion has not been added yet to the script that sets optimization operands
- Half of the FoV is manually picked at the moment and is 38°
- Field angles are picked to split the circular area of the image plane into the rings (circle in the center) of equal area
- N=6
i
αi, rad
cos(αi)
1
0.0000
1.0000
2
0.2513
0.9686
3
0.3554
0.9375
4
0.4353
0.9067
5
0.5027
0.8763
6(N)
0.5620
0.8462
Pixel's filter color
λpeak,nm
range,nm
green
530
510-560
red
600
585-655
blue
450
420-480
- The script to set user-defined custom operands before running optimization in OSLO: set_elphel_operands.ccl